PDF Classification
Efficiency through AI-based, smart automation

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
In the era of digitization, where companies and public administrations are constantly looking for ways to increase their efficiency and minimize manual effort, intelligent document processing proves to be a key tool. Against this backdrop, PDF classification, supported by advanced AI software such as IDA (Intelligent Document Analysis), is gaining increasing significance. It serves not only to recognize documents and extract relevant data but also to classify all kinds of documents (PDF, PNG, JPEG, etc.), thereby significantly optimizing business processes.
What is PDF Classification?
PDF classification is a central component of digital document processing. It refers to the automated categorization of PDF documents into predefined, self-trained categories – regardless of whether there are 10, 100, or 500 document classes. This technology utilizes artificial intelligence and machine learning to analyze content and layout to understand what a document is about. The process helps companies efficiently manage vast amounts of information.
PDF Classification in the Document Processing workflow
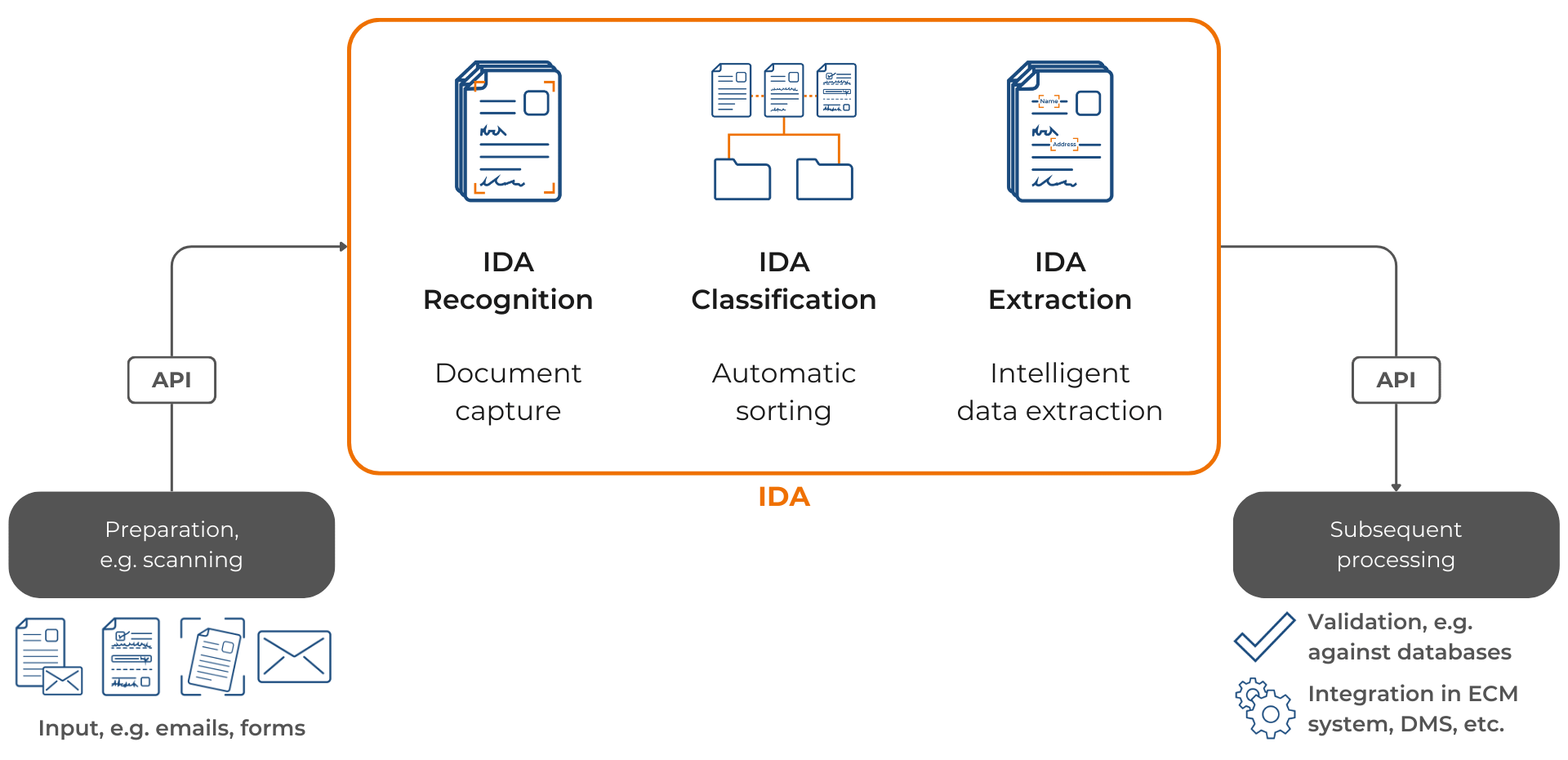
The process of Intelligent Document Processing (IDP) starts after document preparation, such as scanning, with text recognition. Text recognition forms the basis for the subsequent PDF classification. Once the text is captured, the PDFs can be classified by assigning them to the appropriate categories. This second step is crucial for the efficient organization and processing of documents. Then, if necessary, specific contents can be extracted from the classified PDFs, further optimizing the processing access. After the process, matches with existing databases can be set up, and the data can be integrated into an ECM system (Enterprise Content Management) or a DMS (Document Management System).
Manual vs. Rule-based vs. AI-based PDF Classification
Manual Classification: This method is time-consuming and prone to errors, requires a lot of human attention, and is inefficient for large volumes of documents. Its strength lies in the human ability to flexibly handle unforeseen content.
Rule-based Classification: Utilizes predefined criteria to classify documents quickly and consistently. However, this method requires initial effort to define the rules and is less flexible with new document types, necessitating regular updates.
AI-based Classification: Relies on machine learning to recognize patterns in large datasets, improves through continuous learning, and thus continuously increases accuracy. While AI quickly adapts to new data, the initial setup represents a valuable investment that paves the way for highly efficient and automated classification.
What are the Advantages of AI-based PDF Classification?
Automatic PDF classification offers numerous advantages, including:
Time Savings: Manual classification of documents, especially in large quantities, can be very time-consuming. Automatic systems can classify thousands of pages in minutes, which would otherwise take hours or days.
Consistency: Human errors in document classification can lead to inconsistencies (“shit in, shit out”). An automatic system applies the same criteria consistently, resulting in a more uniform document organization.
Improved Accessibility: Categorizing documents into understandable and logical groups significantly improves the findability of information. Users can access needed information faster without having to sift through irrelevant content.
Scalability: Automatic classification systems can be easily scaled to keep pace with the growth of a company or organization. Adding more documents for classification does not require a proportional increase in working hours or costs.
Cost Savings: Although the introduction of an automatic classification system requires an initial investment, the long-term savings can be significant. Less time and labor for manual documentation mean lower operating costs.
Improved Data Analysis and Management: Automatically classified documents facilitate data analysis and management by providing a structured basis for processing and analysis.
The automatic classification of PDF documents has the potential to significantly streamline workflows and increase the efficiency and effectiveness of document management processes.
Use Cases for PDF Classification
Automatic PDF classification is applied in various areas to improve efficiency, accuracy, and document processing speed. Here are some use cases:
Finance and Accounting
Detection and classification of invoices, receipts, bank statements, and other financial documents to automate accounting.
Healthcare
Separation and management of patient records, findings, prescriptions, and other medical documents to improve patient care and comply with data protection regulations.

Government and Public Administration
Classification of incoming letters, applications, decisions, and other official documents to accelerate bureaucracy.
Email Management
Automatic detection and sorting of PDF attachments in emails, for example, invoices, event tickets, or plane tickets.
These and other use cases (education, real estate, customer support and service, etc.) illustrate the versatility and benefits of automatic PDF classification for different industries and areas by reducing manual processes and optimizing document processing.
Challenges in PDF Classification
The classification of documents involves numerous challenges for IDP providers – especially for rule-based software. The challenges are ranging from the diversity and complexity of data to technical limitations. Here are some key challenges that hardly pose a hurdle for AI-based IDA Classification:
Variability of Document Formats: Documents can come in numerous formats (e.g., PDF, Word, JPEG), making classification difficult as each format might require specific processing – and in case of a rule-based system, an own set of rules.
Similarity between Document Categories: Some documents from different categories can closely resemble each other, increasing the risk of misclassification. This can be particularly problematic in areas with a variety of similar forms or document types.
Quality and Resolution of Scanned Documents: The quality and resolution of scanned documents can vary greatly, complicating text capture and recognition and leading to errors in classification.
Changes in Layout and Design: Companies and organizations occasionally change the layout or design of their documents, making existing classification models outdated and less accurate until they are updated.
Adaptability and Scalability: Organizations may struggle to adapt their classification systems quickly enough to keep up with the constant influx of new document types or changes in business processes.
These and other challenges often lead to poor classification rates of 50% – 70%. IDA Classification outshines these rates with accuracies of 90% in most PoCs – f.e. in the Scanning Service Provider Case Study.
IDA Classification
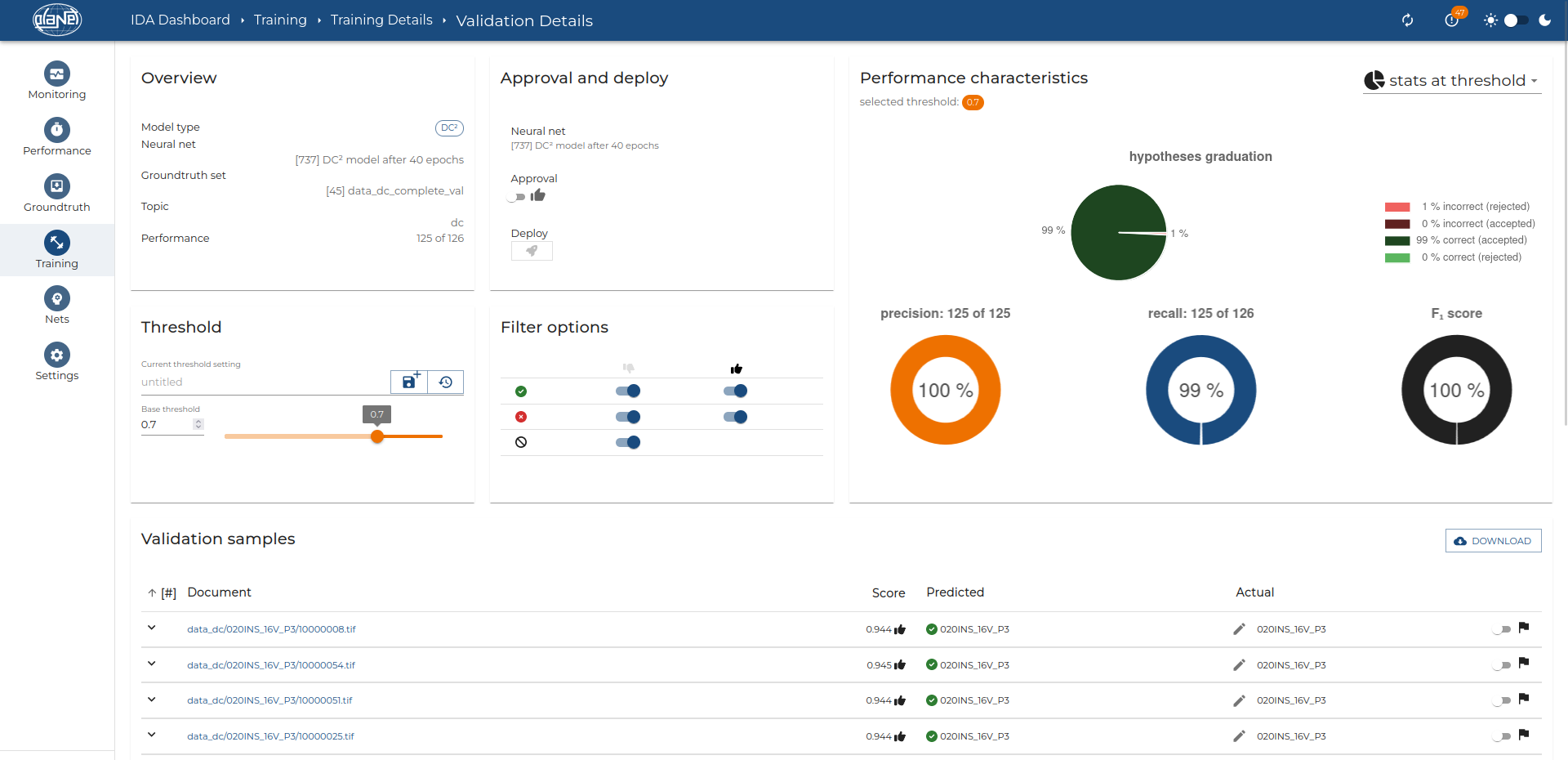
IDA Classification, an advanced technology based on artificial intelligence and not on predefined rules, forms a puzzle piece of your automation. This flexibility makes IDA Classification particularly adaptive; after the initial training, the system can be adjusted to new requirements at any time by adding new classes. Thanks to its ability to classify documents based on advanced visual features, it guarantees highest accuracy and requires little manual post-checking. A useful add-on – document splitting – allows for the division of extensive PDFs into individual files, making them more specific and efficient to process.
Conclusion: A Step Towards the Future
Embracing the classification of digital documents (PDF, PNG, JPEG, etc.) is not just about managing paperwork; it’s about unlocking the full potential of your digital workspace. By integrating efficiency, enhanced security, and strict compliance into your document handling processes, you pave the way for a more organized and streamlined operation. While manual and rule-based methods have their place, the scalability and efficiency of AI-based solutions, like IDA Classification, are indispensable in meeting the complex needs of burgeoning businesses and institutions.
Ready to take a leap into a more efficient future?
Let’s Connect
Imagine a world where document management is no longer a tedious task but a seamless part of your operation, allowing you to focus on what truly matters – growing and scaling your business. Contact us to learn more about the IDA software suite can support you.



