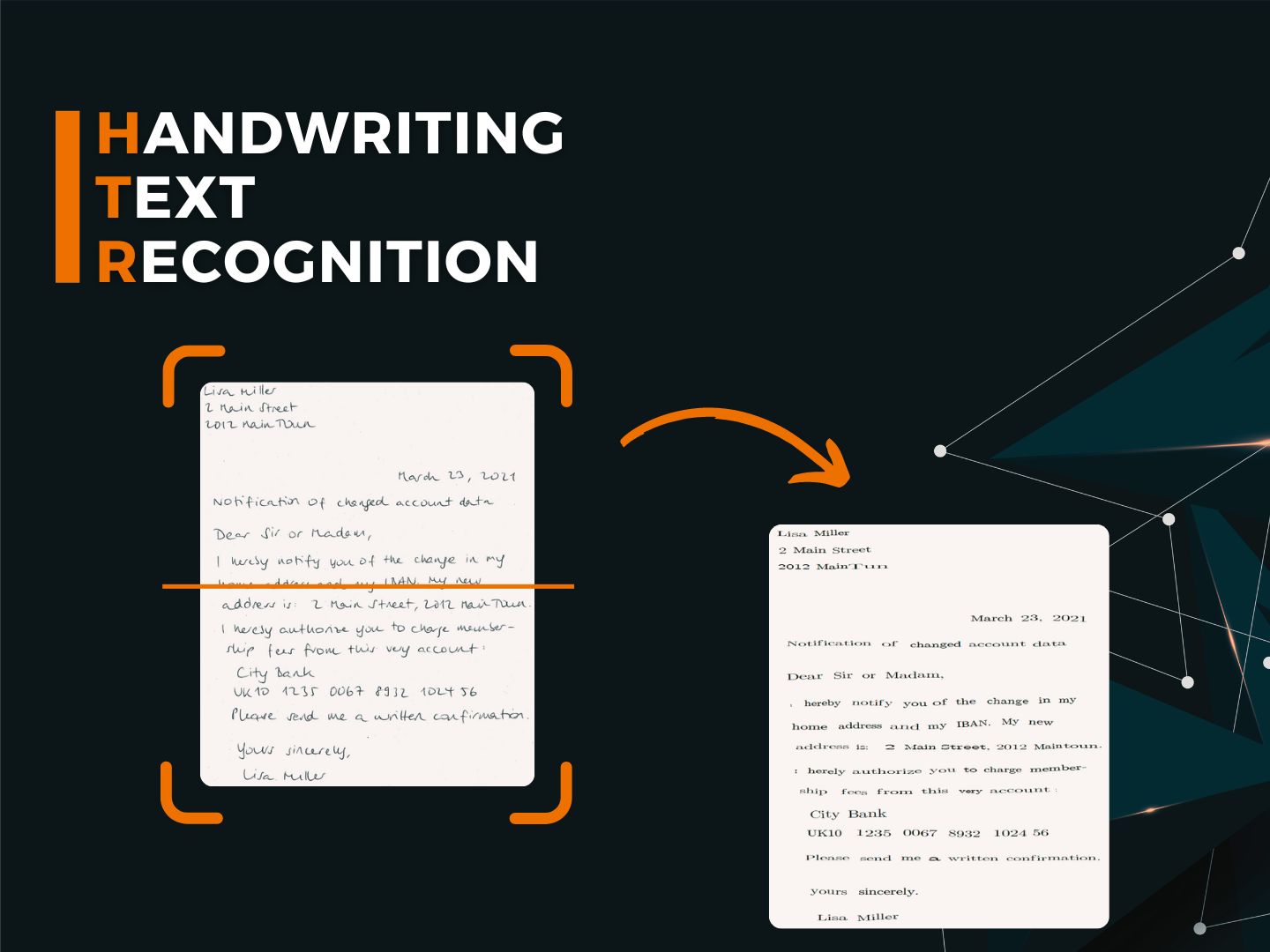
Extrahiert das, was Ihre Prozesse brauchen
Rechnungsbetrag, Kundennummer, Vertragslaufzeit: IDA extrahiert genau die Daten, die Sie brauchen. Mit weniger Validierungsarbeit, höheren Straight-Through-Processing-Raten und qualitativ hochwertigen Daten als Fundament für alle nachgelagerten Schritte.
IDA 5.4 ist verfügbar: jetzt alle Neuerungen ansehen!

Zwei Extraktionsmodi, ein Werkzeug
Je nach Dokumentenstruktur wählen Sie den passenden Modus oder kombinieren beide in einem Workflow.
Was IDA Extraction unterscheidet
Jedes Dokument enthält Informationen, die Prozesse weiterbringen, wenn sie rechtzeitig und fehlerfrei erfasst werden.
Regelwerke scheitern, wenn sich Layouts ändern. Ohne Verifizierung bleiben LLM-Fehler im Prozess unsichtbar. IDA Extraction löst beides.
No-Code-Training mit automatischer Layout-Erkennung
Regelbasierte Extraktionslösungen verlangen aufwändige Konfiguration für jedes neue Dokumentenlayout. ExA erkennt wiederkehrende Ankerpunkte automatisch und gruppiert ähnliche Layouts. Das Training der Extraktionsfelder findet vollständig im Browser statt.
Halluzinationsschutz durch OCR-Verifizierung
KI-Halluzinationen sind bei LLM-basierter Extraktion ein bekanntes Risiko. IDA begegnet dem mit einem integrierten Verifizierungsschritt: Die Ausgaben des LLM werden automatisch mit der OCR-Transkription von IDA Recognition abgeglichen. Was das Sprachmodell nicht aus dem Dokument belegen kann, wird nicht weitergegeben.
Prompt-Validierung vor Produktiveinsatz
LLM-basierte Extraktion bringt eine neue Art von Unsicherheit mit: Wie verlässlich ist ein Prompt wirklich und wie schneidet er im Vergleich zu einer anderen Formulierung ab? Mit IDA testen Sie Prompts gegen benutzerdefinierte Ground-Truth-Sets und vergleichen Varianten objektiv, bevor das Modell in die Produktion geht. Aus dem Bauchgefühl wird eine messbare Entscheidung.
IDA Extraction in Aktion
ExA und LLM Entity Extraction – in fünf Minuten erklärt.
> 91%
Automatisierungsrate
> 80%
Zeitersparnis durch Automatisierung
0
Regelwerke
5 Tage
Setup-Zeit
Technische Details
Kunden und Partner, die uns vertrauen