PDF-Klassifikation
Effizienz durch KI-basierte, intelligente Automatisierung

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
In der Ära der Digitalisierung, wo Unternehmen und öffentliche Verwaltungen beständig nach Wegen suchen, ihre Effizienz zu steigern und den manuellen Aufwand zu minimieren, erweist sich die intelligente Dokumentenverarbeitung als ein Schlüsselinstrument. Vor diesem Hintergrund gewinnt die PDF-Klassifikation, unterstützt durch fortschrittliche KI-Software wie IDA (Intelligent Document Analysis), zunehmend an Bedeutung. Sie dient dazu, Dokumente nicht nur zu erkennen und relevante Daten zu extrahieren, sondern auch jegliche Dokumente (PDF, PNG, JPEG, etc.) zu klassifizieren und somit Geschäftsprozesse erheblich zu optimieren.
Was ist PDF-Klassifikation?
Die PDF-Klassifikation ist ein zentraler Baustein der digitalen Dokumentenverarbeitung. Sie bezieht sich auf die automatisierte Einordnung von PDF-Dokumenten in vordefinierte, selbst trainierte Kategorien – ganz egal ob 10, 100 oder 500 Klassen. Diese Technologie macht Gebrauch von künstlicher Intelligenz und maschinellem Lernen, um Inhalte und Layout zu analysieren. Damit versteht die KI, worum es in einem Dokument geht. Der Prozess hilft Unternehmen, riesige Mengen an Informationen effizient zu verwalten.
PDF-Klassifikation im Prozess der Verarbeitung von Dokumenten
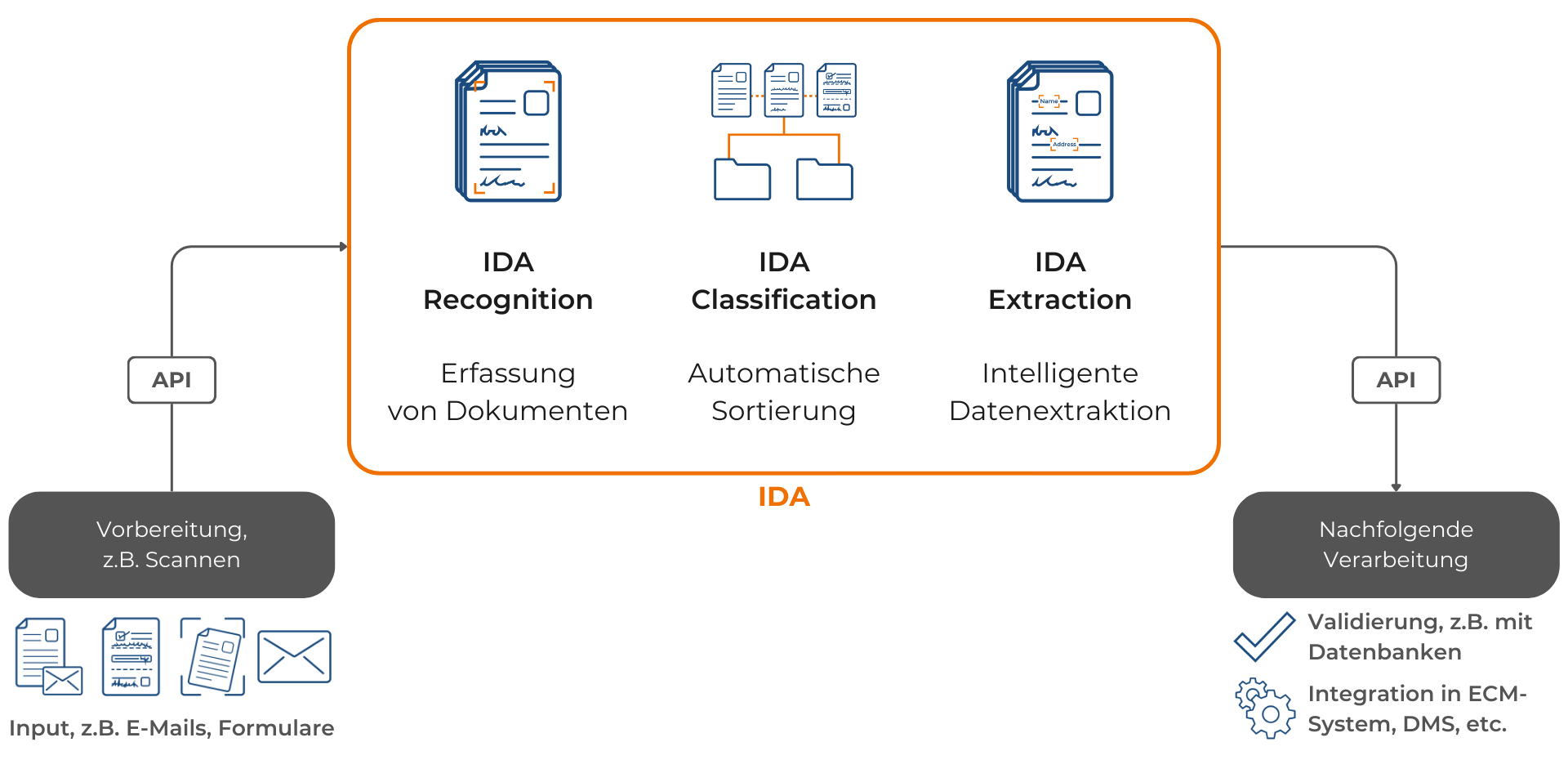
Der Prozess der intelligenten Dokumentenverarbeitung (IDP) beginnt nach der Vorbereitung der Dokumente, wie dem Scannen, mit der Texterkennung. Die Texterkennung bildet die Basis für die nachfolgende PDF-Klassifikation. Sobald die Texte erkannt sind, werden die PDFs klassifiziert, indem sie entsprechenden Kategorien zugeordnet werden. Dieser zweite Schritt ist entscheidend für die effiziente Organisation und Verarbeitung von Dokumenten. Anschließend können bei Bedarf spezifische Inhalte aus den klassifizierten PDFs extrahiert werden, was den Verarbeitungszugang weiter optimiert. Nach dem Prozess können Abgleiche mit bestehenden Datenbanken eingerichtet werden, und die Daten können in ein ECM-System (Enterprise Content Management) oder DMS (Dokumentenmanagementsystem) integriert werden.
Manuelle vs. Regelbasierte vs. KI-basierte Klassifikation
Manuelle Klassifikation: Diese Methode ist zeitaufwändig und fehleranfällig, erfordert viel menschliche Aufmerksamkeit und ist bei großen Dokumentmengen ineffizient. Ihre Stärke liegt in der menschlichen Fähigkeit, unvorhergesehene Inhalte flexibel zu handhaben.
Regelbasierte Klassifikation: Nutzt festgelegte Kriterien, um Dokumente schnell und konsistent zu klassifizieren. Diese Methode erfordert allerdings anfänglichen Aufwand, um die Regeln zu definieren, und ist weniger flexibel bei neuen Dokumenttypen, was regelmäßige Updates notwendig macht.
KI-basierte Klassifikation: Setzt auf Machine Learning, um Muster in großen Datenmengen zu erkennen, verbessert sich durch fortlaufendes Lernen und steigert so kontinuierlich die Genauigkeit. Während die KI sich schnell an neue Daten anpasst, stellt die anfängliche Einrichtung eine wertvolle Investition dar, die die Weichen für eine hochgradig effiziente und automatisierte Klassifikation stellt.
Was sind die Vorteile der KI-basierten PDF-Klassifikation?
Die Vorteile der automatischen PDF-Klassifikation sind vielfältig und umfassen u.a.:
Zeitersparnis: Manuelle Klassifikation von Dokumenten, insbesondere in großen Mengen, kann sehr zeitintensiv sein. Automatische Systeme können Tausende von Seiten in Minuten klassifizieren, was sonst Stunden oder Tage in Anspruch nehmen würde.
Konsistenz: Menschliche Fehler bei der Dokumentklassifikation können zu Inkonsistenzen („shit in, shit out“) führen. Ein automatisches System wendet konsistent dieselben Kriterien an, was zu einer einheitlicheren Dokumentenorganisation führt.
Verbesserte Zugänglichkeit: Durch das Kategorisieren von Dokumenten in verständliche und logische Gruppen wird die Auffindbarkeit der Informationen erheblich verbessert. Nutzer können schneller auf benötigte Informationen zugreifen, ohne sich durch irrelevante Inhalte wühlen zu müssen.
Skalierbarkeit: Automatische Klassifikationssysteme können leicht skaliert werden, um mit dem Wachstum eines Unternehmens oder einer Organisation Schritt zu halten. Das Hinzufügen weiterer Dokumente zur Klassifizierung erfordert keinen proportionalen Anstieg der Arbeitszeit oder -kosten.
Kostenersparnis: Obwohl die Einführung eines automatischen Klassifikationssystems eine anfängliche Investition erfordert, können die langfristigen Einsparungen erheblich sein. Weniger Zeit- und Arbeitsaufwand für die manuelle Dokumentation bedeutet niedrigere Betriebskosten.
Verbesserte Datenanalyse und -verwaltung: Automatisch klassifizierte Dokumente erleichtern die Datenanalyse und das Datenmanagement, indem sie eine strukturierte Grundlage für die Verarbeitung und Analyse bieten.
Die automatische Klassifikation von Dokumenten hat also das Potenzial, Arbeitsabläufe erheblich zu optimieren und die Effizienz und Effektivität von Dokumentenverwaltungsprozessen zu steigern.
Anwendungsfälle der PDF-Klassifikation
Die automatische PDF-Klassifikation findet in verschiedensten Bereichen Anwendung, um Effizienz, Genauigkeit und die Verarbeitungsgeschwindigkeit von Dokumenten zu verbessern. Hier sind einige Anwendungsfälle:
Finanzwesen und Buchhaltung
Erkennung und Klassifizierung von Rechnungen, Quittungen, Kontoauszügen und anderen finanziellen Dokumenten zur Automatisierung der Buchführung.
Gesundheitswesen
Trennung und Verwaltung von Patientenakten, Befunden, Rezepten und anderen medizinischen Dokumenten zur Verbesserung der Patientenversorgung und zur Einhaltung von Datenschutzvorschriften.

Öffentliche Verwaltung
Klassifizierung eingehender Schreiben, Anträge, Bescheide und anderer Amtsdokumente zur Beschleunigung der Bürokratie.
E-Mail-Management
Automatische Erkennung und Sortierung von PDF-Anhängen in E-Mails, zum Beispiel Rechnungen, Event-Tickets oder Flugtickets.
Diese und weitere Anwendungsfälle (Bildungswesen, Immobilienwesen, Kundenbetreuung und -service, etc.) verdeutlichen die Vielseitigkeit und den Nutzen der automatischen PDF-Klassifikation für unterschiedliche Branchen und Bereiche, indem sie manuelle Prozesse reduzieren und die Dokumentenverarbeitung optimieren.
Herausforderungen bei der PDF-Klassifikation
Die Klassifikation von Dokumenten bringt zahlreiche Herausforderungen für IDP-Anbieter mit sich – insbesondere für regelbasierte Software. Die Herausforderungen reichen von der Vielfalt und Komplexität der Daten bis hin zu technischen Einschränkungen. Hier sind einige Schlüsselherausforderungen, die für die KI-basierte Lösung IDA Classification kaum Probleme darstellen:
Variabilität der Dokumentenformate: Dokumente können in zahlreichen Formaten vorliegen (z.B. PDF, Word, JPEG), was die Klassifizierung erschwert, da jedes Format eine spezifische Verarbeitung benötigen könnte.
Ähnlichkeit zwischen Dokumentenkategorien: Manche Dokumente verschiedener Kategorien können sich stark ähneln, was die Gefahr von Fehlklassifikationen erhöht. Dies kann besonders in Bereichen mit einer Vielzahl ähnlicher Formulare oder Dokumententypen problematisch sein.
Qualität und Auflösung eingescannter Dokumente: Die Qualität und Auflösung eingescannter Dokumente kann stark variieren, was Texterfassung und -erkennung erschwert und zu Fehlern in der Klassifizierung führt.
Änderungen im Layout und Design: Firmen und Organisationen ändern gelegentlich das Layout oder Design ihrer Dokumente, was bestehende Klassifikationsmodelle veraltet und weniger genau machen kann, bis sie auf den neuesten Stand gebracht werden.
Anpassungsfähigkeit und Skalierbarkeit: Organisationen können Schwierigkeiten haben, ihre Klassifikationssysteme schnell genug anzupassen, um mit dem stetigen Zustrom neuer Dokumententypen oder Änderungen in den Geschäftsprozessen Schritt zu halten.
Diese und weitere Herausforderungen führen nicht selten zu schlechten Klassifizierungsraten von 50 % – 70 %. IDA Classification stellt diese Raten mit Genauigkeiten von ~ 90 % bei den meisten PoCs bereits in den Schatten – z.B. in der Scanning Service Provider Case Study.
IDA Classification
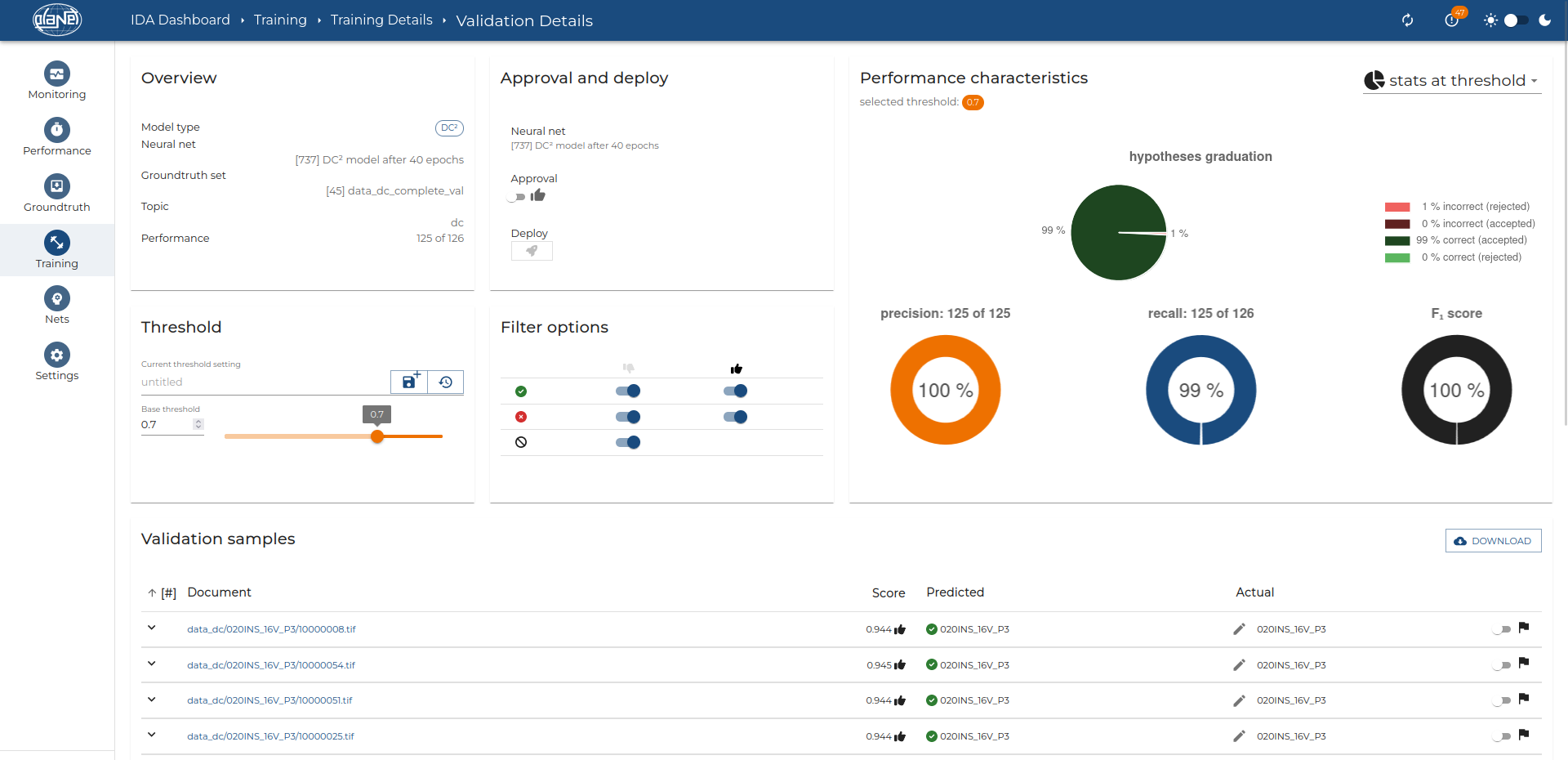
Ein Puzzleteil Ihrer Automatisierung bildet IDA Classification, eine fortschrittliche Technologie, die auf künstlicher Intelligenz beruht, nicht auf starren, vordefinierten Regeln. Diese Flexibilität macht IDA Classification besonders adaptiv; nach dem ursprünglichen Training kann das System durch Hinzufügen neuer Klassen jederzeit an neue Anforderungen angepasst werden. Dank seiner Fähigkeit, Dokumente anhand fortgeschrittener visueller Merkmale zu klassifizieren, garantiert es höchste Genauigkeit und erfordert nur wenig manuelle Nachkontrolle. Ein nützliches Add-on – das Document Splitting – ermöglicht es, umfangreiche PDFs in einzelne Dateien aufzuteilen und somit spezifischer und effizienter zu verarbeiten.
Fazit: Ein Schritt in Richtung Zukunft
Die Klassifizierung digitaler Dokumente (PDF, PNG, JPEG etc.) zu umarmen, bedeutet nicht nur, Papierkram zu verwalten; es geht darum, das volle Potenzial Ihres digitalen Arbeitsbereichs zu erschließen. Indem Sie Effizienz, verbesserte Sicherheit und strenge Konformität in Ihre Dokumentenverarbeitungsprozesse integrieren, bahnen Sie den Weg für einen organisierteren und effizienteren Betrieb. Obwohl manuelle und regelbasierte Ansätze ihren Platz haben, sind die Skalierbarkeit und Effizienz KI-basierter Lösungen, wie IDA Classification, unverzichtbar, um den komplexen Bedürfnissen wachsender Unternehmen und Institutionen gerecht zu werden.
Bereit für einen Sprung in eine effizientere Zukunft?
Let’s Connect
Stellen Sie sich eine Welt vor, in der Dokumentenmanagement nicht länger eine mühsame Aufgabe ist, sondern ein nahtloser Teil Ihres Unternehmens, der es Ihnen ermöglicht, sich auf das zu konzentrieren, was wirklich zählt – Wachstum und Skalierung. Kontaktieren Sie uns, um mehr darüber zu erfahren, wie die IDA Software-Suite Sie unterstützen kann.