Data Extraction Beginner Guide

- 1
- 2
- 3
- 4
- 5
- 6
- 7
Welcome to the Data Extraction Beginner Guide! Building upon the existing Beginner Guides: OCR/ICR and Document Classification, this guide aims to provide you with a comprehensive understanding of extracting data in the field of Intelligent Document Processing (IDP).
In today’s digital age, businesses are flooded with an overwhelming amount of data. Unlocking valuable insights from documents and unstructured information is crucial for efficient decision-making and automation. This is where Intelligent Document Processing (IDP) comes into play, with extracting relevant data being one step in the whole process. In this beginner’s guide, we will dive into the world of data extraction within the IDP framework, with a focus on how PLANET AI’s technology IDA – Intelligent Document Analysis – can streamline and simplify this crucial aspect of document processing.
What is Data Extraction?
Data extraction is a fundamental process to automatically extract specific data points from documents. PLANET AI utilizes advanced key-value pair extraction that empowers users to easily specify the data points they wish to capture. This involves identifying and isolating relevant details such as text, numerical values, dates, checkboxes, and more. Positional information proves valuable for subsequent downstream tasks, such as validation.
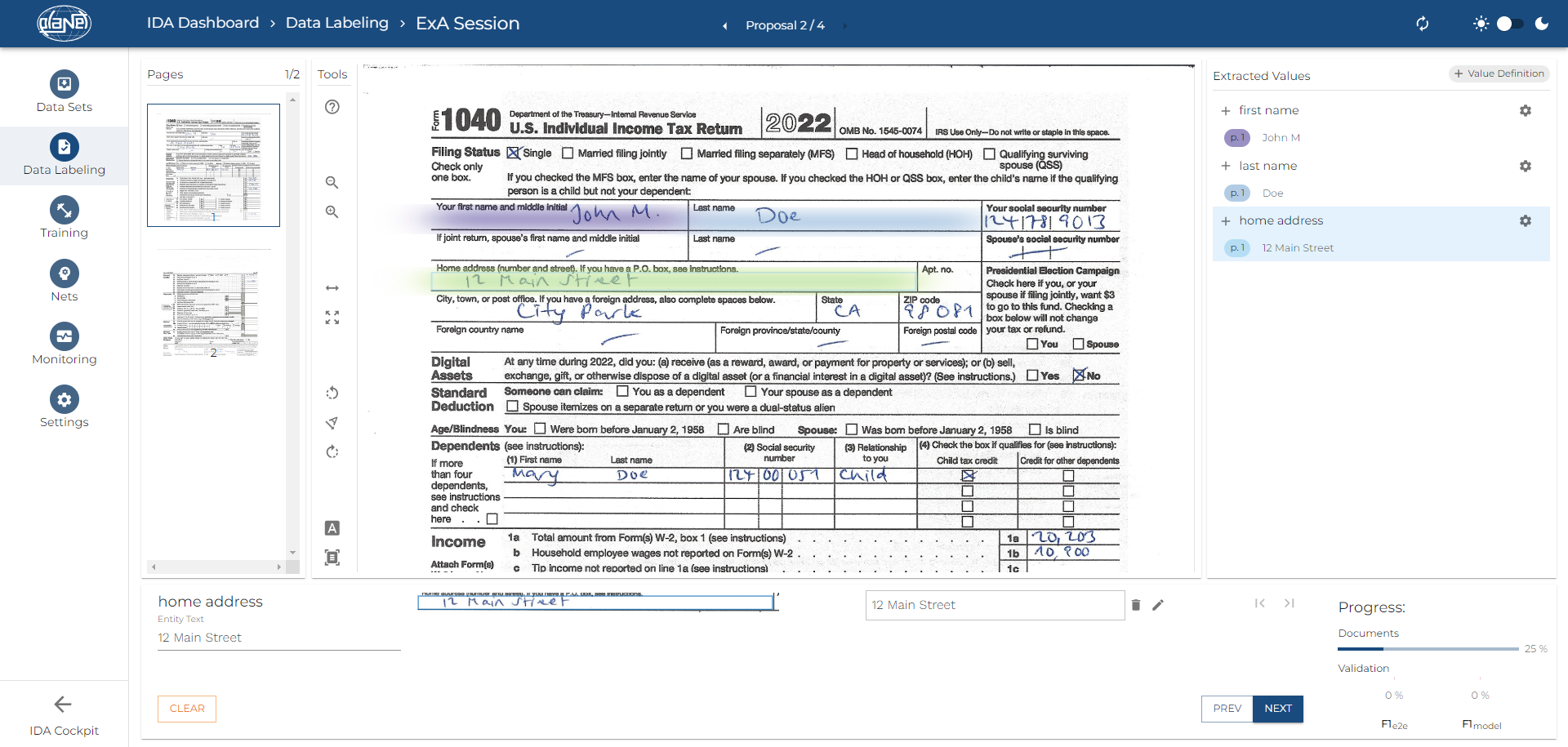
Data Extraction Training
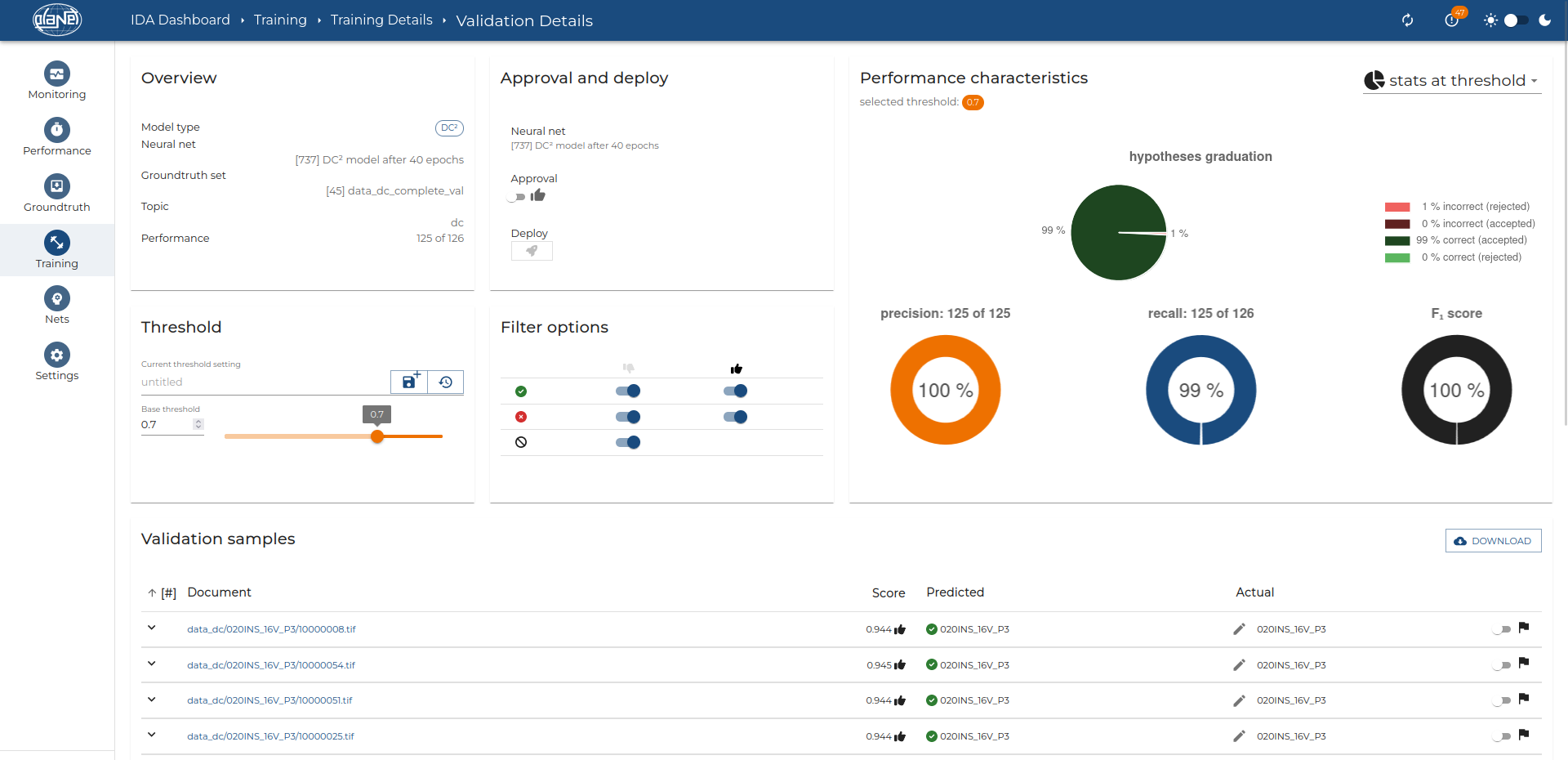
The remarkable aspect of data extraction training within IDP, such as PLANET AI’s technology, is its accessibility to individuals with limited technical knowledge. The complexity of the training depends on the documents being processed. In simpler cases, AI models can be trained with as few as five sample documents. This training process empowers the AI to recognize patterns and extract data accurately.
Automatic Data Extraction
Once trained, these AI models can operate autonomously, enabling automatic data extraction from a wide range of documents. This automation streamlines workflows, reduces manual effort, and minimizes errors, making document processing more efficient and reliable.
Data Extraction in the IDP Process

Extracting data is a part of the IDP process, encompassing three key steps:
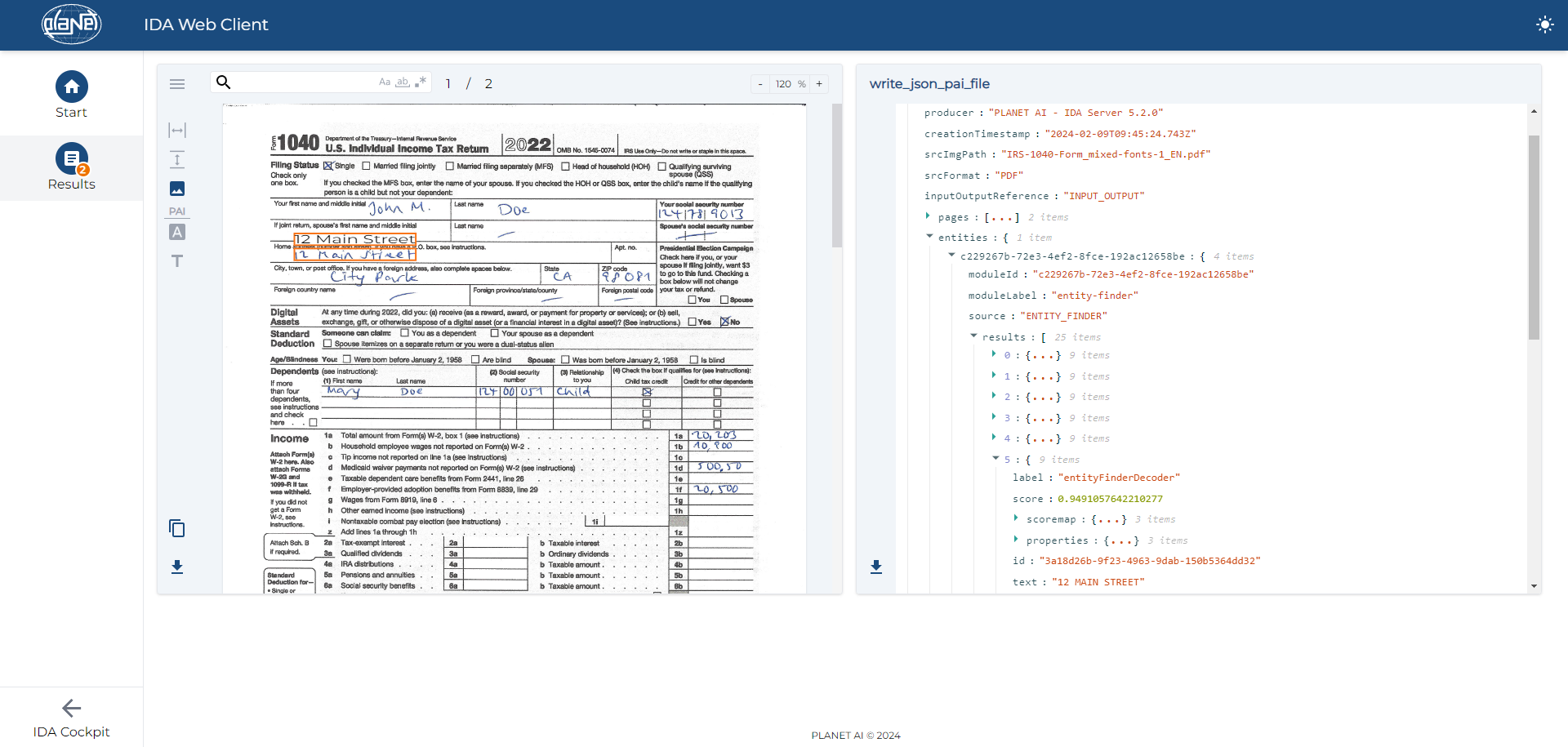
1 – Capture of Documents
This initial step involves capturing documents with both handwriting and machine-print, transforming them into a digital format for further processing.
Optional – 2 – Document Classification
Next, documents are categorized into individually trained classes or types, streamlining their handling within the IDP system.
3 – Data Extraction
In this guide, we will primarily explore the 3rd step, which is the core component to extract valuable information from documents.
In essence, data extraction is the systematic collection and retrieval of specific data points from documents. This involves identifying and extracting relevant information, essentially converting unstructured data into structured, actionable insights.
Upcoming LLM Extraction
Excitingly, PLANET AI is on the verge of introducing LLM (Large Language Model) entity extraction. It will provide users with a tool to automatically extract data from unstructured documents by using simple queries. This innovative feature is set to revolutionize data extraction. Keep an eye out for this upcoming feature, as it promises to enhance the precision and versatility of extracting relevant data in document processing.
Conclusion
In this Beginner Guide, we’ve explored the essential steps of Intelligent Document Processing (IDP), emphasizing the crucial role of extracting data. Efficiently extracting insights from documents is vital in today’s data-driven world. Our aim was to showcase how PLANET AI’s technology simplifies this process.
Let’s Connect
If you’re ready to unlock the potential of data extraction for your business or have technical questions about security, implementation, and more, our expert team is ready to assist you. Contact us today to embark on a journey towards more efficient and data-driven document processing with PLANET AI.



