Entity Extraction
A Key Component of Modern Data Processing

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
In today’s digital world, the ability to swiftly and accurately extract information from documents is more crucial than ever. Businesses and organizations of all sizes face the daily challenge of converting large volumes of unstructured data into usable information. This is where entity extraction comes into play within the context of Intelligent Document Processing (IDP). This blog post will take a detailed look at what entity extraction is, how it works within the framework of IDP, and why it is essential for businesses.
What is Entity Extraction?
Entity extraction, also known as entity recognition, is an information retrieval process aimed at identifying and classifying specific information from text. These pieces of information, or “entities,” can include names of people, organizations, places, dates, times, quantities, monetary values, and more. Extracting these data transforms unstructured data into a structured form, simplifying analysis and processing.
Entity Extraction in the IDP Context
Within the IDP context, entity extraction plays a pivotal role in extracting valuable information from a variety of document types such as invoices, contracts, emails, and other business documents. It’s not just about identifying specific data; it’s also about understanding the relationship and context of these data to each other to correctly integrate them into existing business processes or databases. By automatically recognizing relevant entities like contract numbers, amounts, dates, and involved parties, IDP systems efficiently capture document contents and prepare them for further processes. The challenge lies in the diversity of document formats and the complexity of language, highlighting the need for advanced machine learning and AI algorithms to ensure high accuracy in data extraction.
A powerful OCR – The Key for efficient Entity Extraction
Efficient entity extraction requires a powerful Optical Character Recognition (OCR) to avoid the principle of “garbage in, garbage out.” The quality and accuracy of text extracted from various documents are crucially dependent on the OCR’s ability to correctly convert digital data into editable text. Modern OCR systems can recognize and process even complex fonts and layouts. This high level of detection performance is essential to ensure that the subsequent entity extraction delivers precise information, thus optimizing the entire data processing workflow.
Entity Extraction with IDA
The innovative extraction technologies of the IDA – Intelligent Document Analysis – software suite revolutionize data capture and processing by providing optimized solutions for both structured and unstructured documents. These advanced methods enable quick, precise extraction and processing of relevant data, supported by modern AI models.
Structured Documents – Zonal Data Extraction
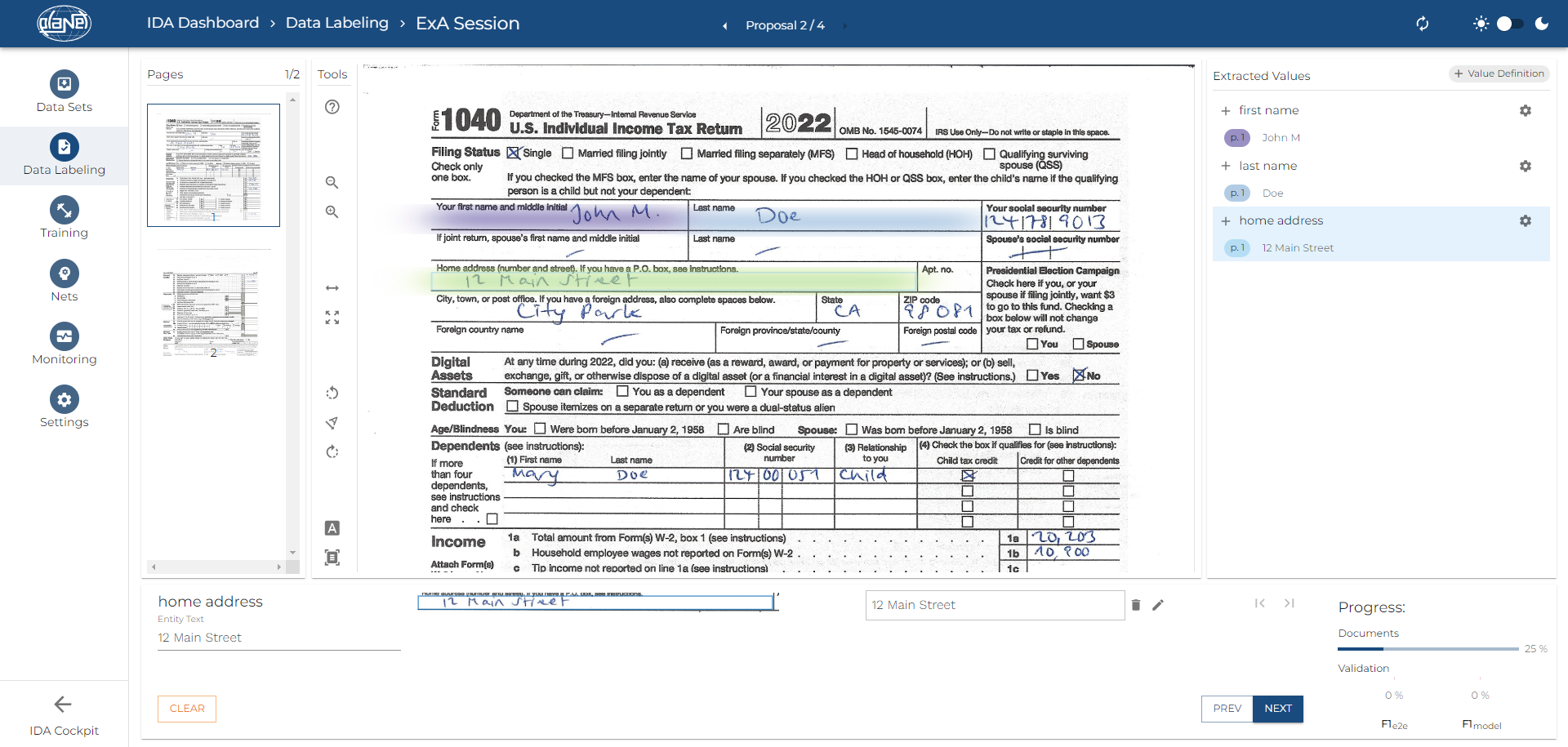
For structured documents, such as invoices or forms, IDA uses zonal data extraction. This technique utilizes few-shot learning to quickly adapt AI models to specific data fields. This leads to efficient and accurate capture of desired information without extensive manual settings or preparatory work.
Unstructured Documents – LLM-based Extraction
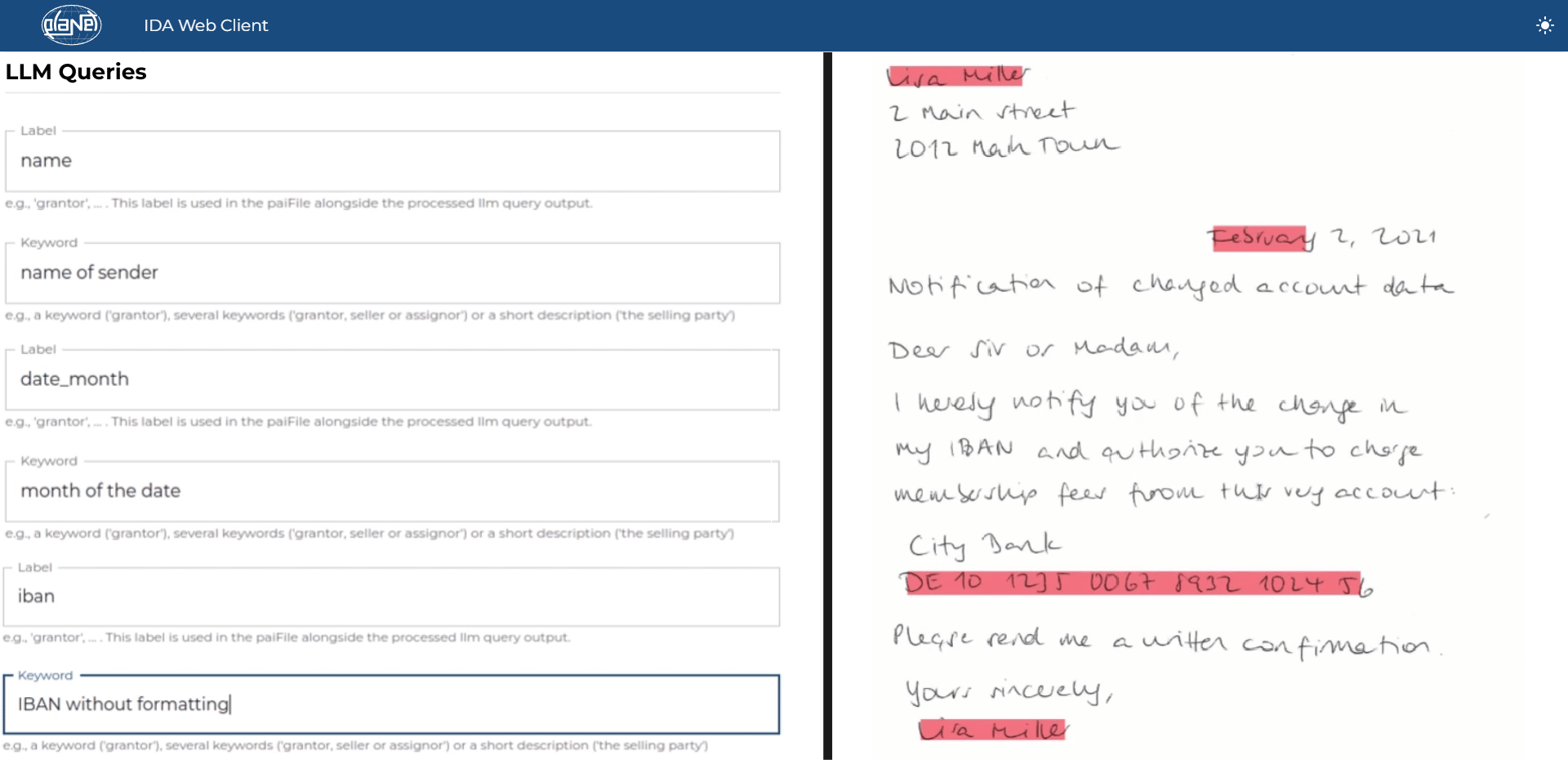
In the case of unstructured documents, such as emails or reports, IDA relies on extraction based on large language models (LLMs). These can understand complex texts and filter out relevant information. Thanks to LLM technology, valuable data are efficiently extracted from text-rich, unstructured documents, significantly improving data capture and analysis.
Improving Data Quality and Accessibility
The automatic extraction and classification of entities not only accelerate data processing but also enhance its accuracy. Error-prone manual entries are minimized and the consistency of data processing is improved.
Entity Extraction Applications in the IDP Context
The application of entity extraction in the IDP context includes numerous areas where specific information is extracted from documents. Here are some examples:
Invoice Processing
In invoices, entity extraction can automatically capture relevant information such as invoice number, date, amounts, tax details, and supplier details. This significantly simplifies accounting processes.
Contract Management
In contract management, entity recognition can be used to extract data such as contracting parties, start and end dates, contract terms, payment clauses, and penalties from contracts. This assists in the automation of compliance checks and contract monitoring.

Customer Onboarding
In the banking and insurance sectors, entity extraction is useful for automatically extracting information such as names, dates of birth, addresses, and other personal details from ID documents and incorporating them into customer databases.
Email and Communication Management
Information such as contact details, appointments, inquiries, or order numbers can be extracted from incoming emails or messages to speed up processing and initiate relevant processes.
By deploying entity extraction in these and other use cases, companies can not only save time and resources but also improve data quality and reduce human errors.
Conclusion
Entity extraction is an indispensable part of intelligent document processing, enabling businesses to unlock the full potential of their data. By automating data capture and classification, organizations can increase their efficiency, enhance the accuracy of data processing, and make better-informed decisions. With the continuous improvement of underlying technologies, entity extraction will continue to play a key role in transforming the way we handle information.
Let’s Connect
Would you like to learn how our technologies can help automate your data management? Do not hesitate to contact us! We are happy to discuss your specific requirements and offer tailor-made solutions that add true value to your business processes. Contact us now to take the first step towards more efficient data processing and improved decision-making.


