PDF Data Extraction
Efficient and Automatic Data Extraction with AI

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
In a world where data is considered the new gold, manually extracting information from documents – PDF, PNG, JPG, etc. – is not only time-consuming but also prone to errors. This is where the true power of Intelligent Document Processing (IDP) software shines. Powerful OCR (Optical Character Recognition) and ICR (Intelligent Character Recognition) technologies, as utilized in the advanced IDA software suite, play a crucial role in effectively addressing the challenges of automatic data extraction. Without such technologies, we would be trapped in an endless cycle of “garbage in, garbage out” resulting in continual manual reprocessing.
What is PDF Data Extraction?
PDF data extraction is the process of transforming information from PDF documents into a structured, machine-readable format. This technique is crucial because PDFs are widely used to disseminate and store information. The challenge lies in extracting data in such a way that it becomes directly usable for further analysis or processing. Advanced technologies like OCR and ICR are central to this, as they detect and extract complex information, converting static PDF content into dynamic data that delivers real value.
PDF Data Extraction in the IDP Process
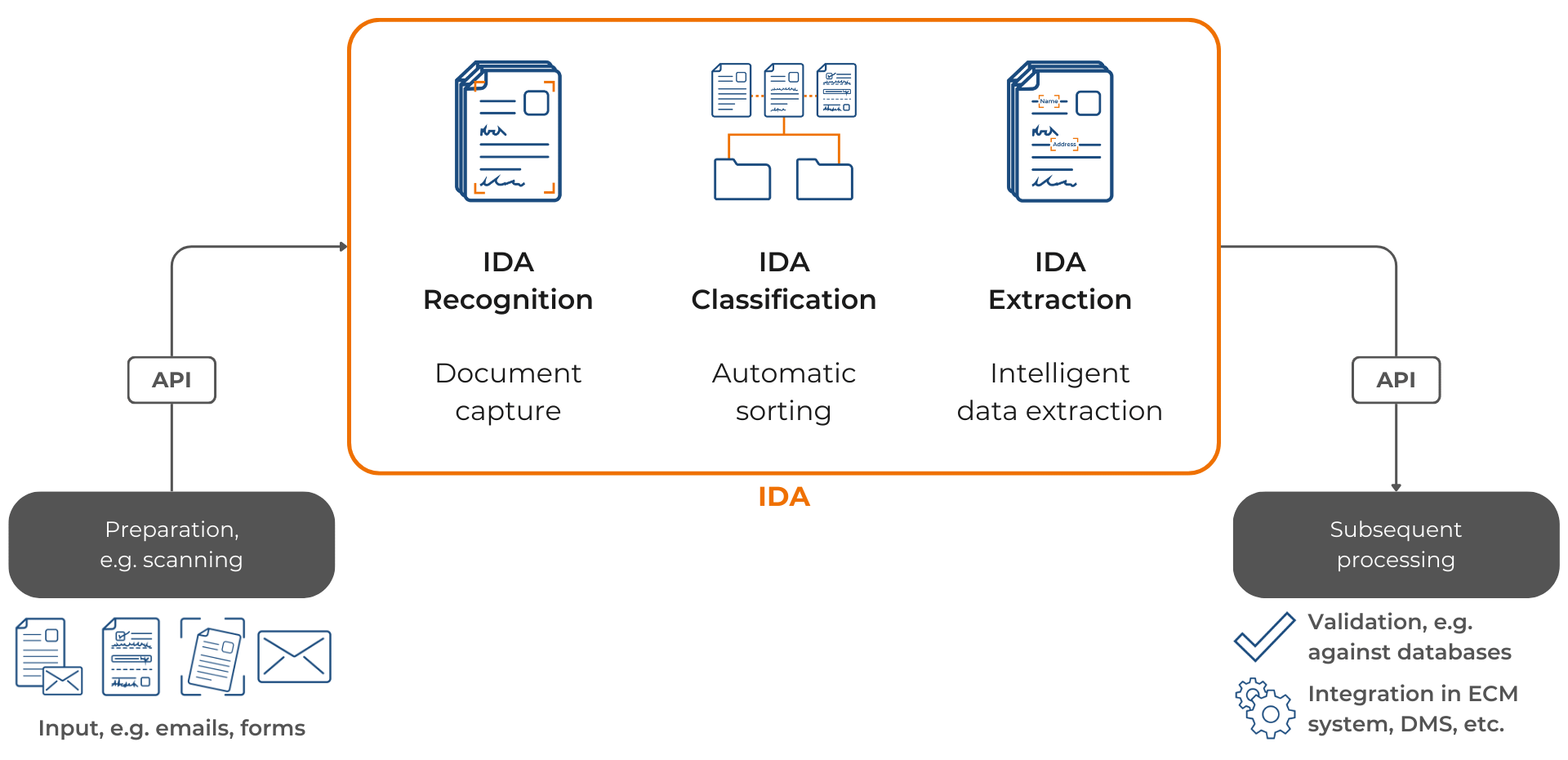
Data extraction is central to the process of intelligent document processing, which starts after the preparation of documents, such as scanning. The digital capture of documents through OCR and ICR technologies sets the quality foundation for all subsequent processing steps. After capture, documents can be classified using AI, and relevant data extracted from the PDF documents. The subsequent phase integrates the processed data by validating it against databases into existing ECM systems or DMS, not only speeding up business processes but also ensuring efficient information flow.
Types of PDF Data Extraction
In automatic data extraction from documents, we mainly differentiate between two techniques, depending on the type of document.
Zonal Data Extraction – for structured documents
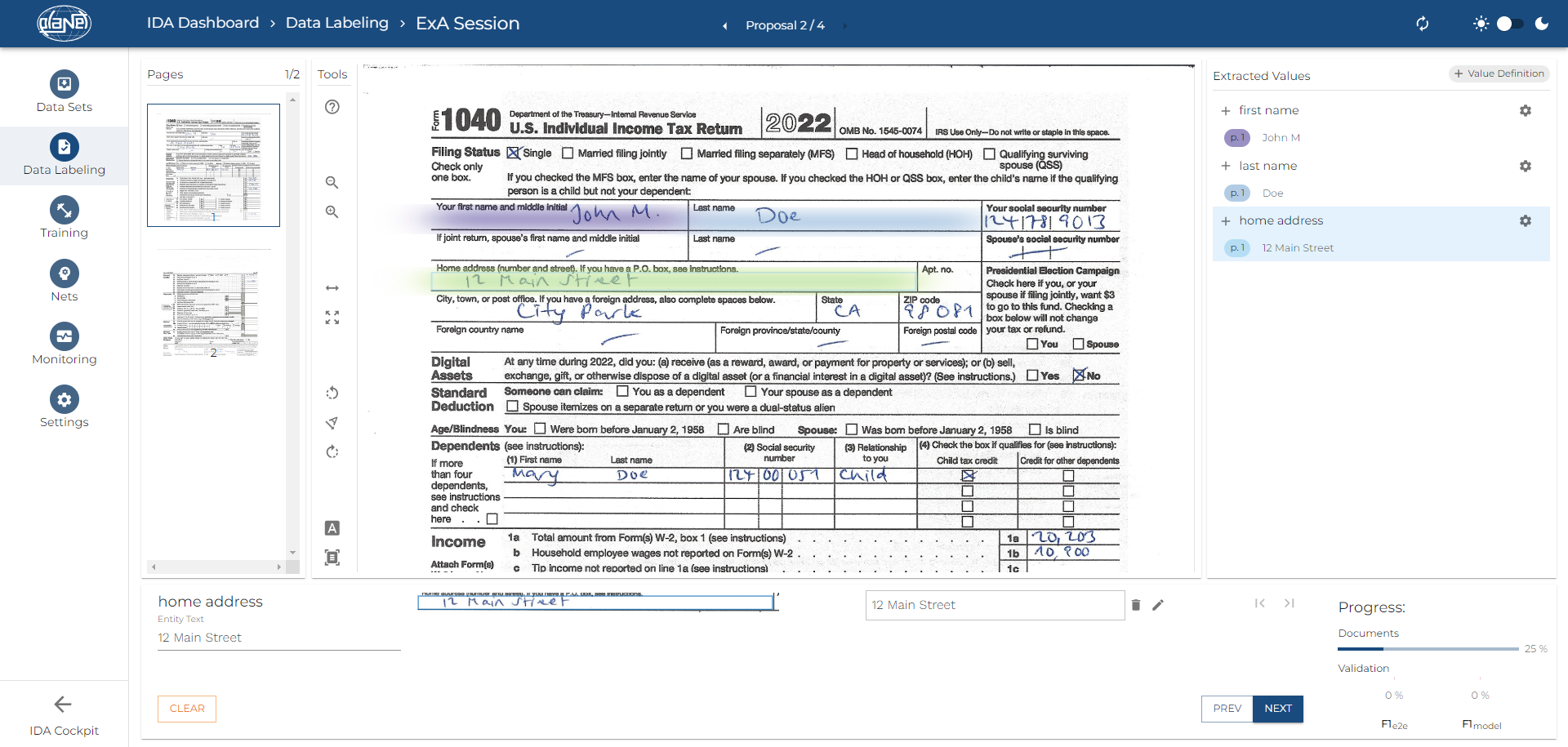
The Zonal Data Extraction is ideal for structured and semi-structured documents, such as forms, invoices, etc., where specific data is found in predefined areas. During the training process of the AI, the user marks the specific zones from which information should be extracted in various sample documents. After training is complete, the AI is capable of automatically extracting data from the corresponding areas in new incoming documents.
LLM Entity Extraction – for unstructured documents
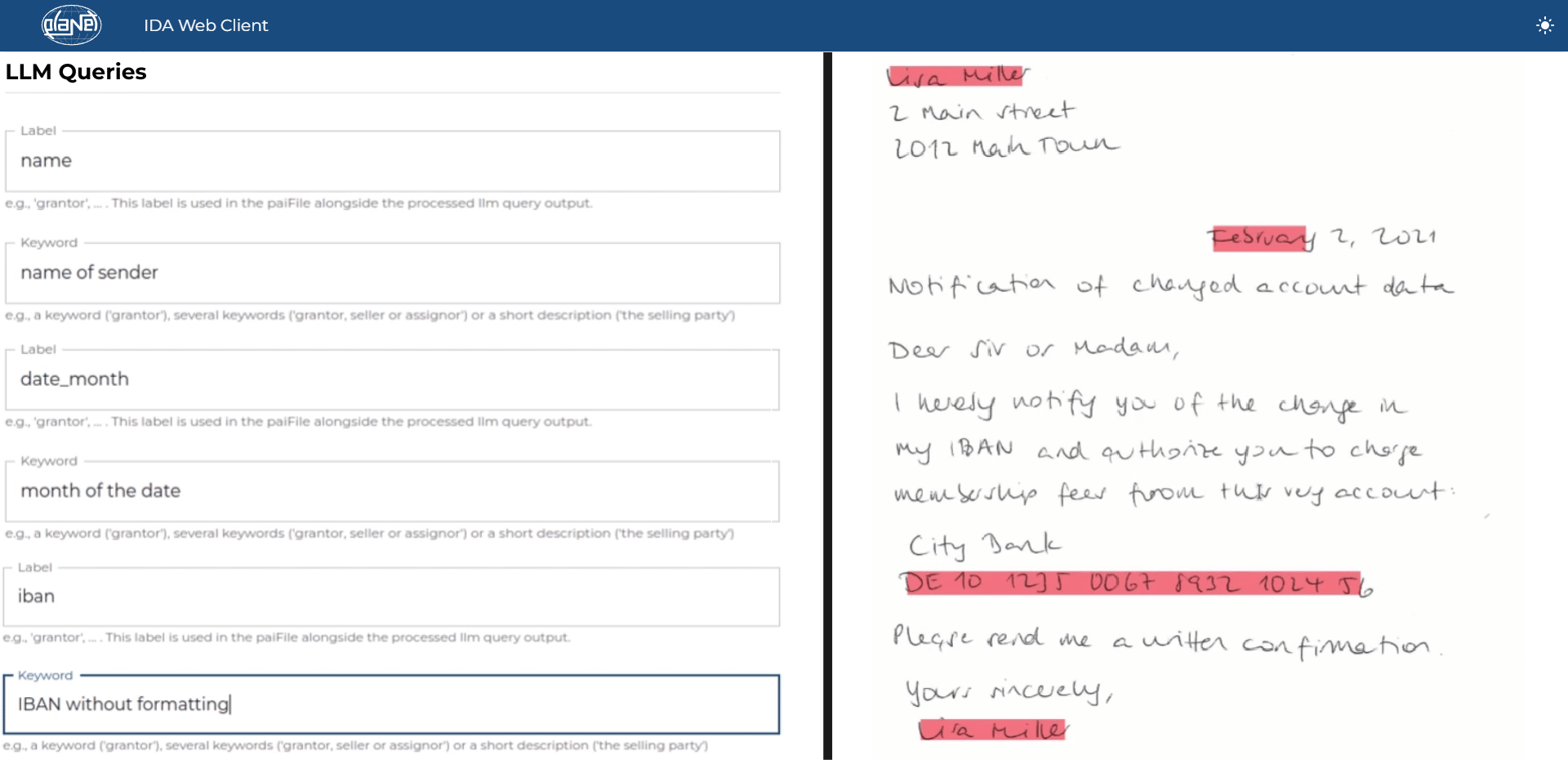
The LLM Entity Extraction is ideal for structured and semi-structured documents, such as forms, invoices, etc., where specific data is found in predefined areas. During the training process of the AI, the user marks the specific zones from which information should be extracted in various sample documents. After training is complete, the AI is capable of automatically extracting data from the corresponding areas in new incoming documents.
Together, these approaches enable comprehensive and flexible data extraction from all types of documents, making them indispensable tools in digital data processing.
What are the Advantages of PDF Data Extraction?
In the era of digitalization and big data, companies face the challenge of efficiently processing and utilizing vast amounts of data. Here, automatic data extraction using AI offers a solution to meet these challenges.
Time Savings: Automation of the data extraction process can result in significant time savings as it eliminates the manual effort of reading, understanding, and entering data from documents into digital systems.
Cost Efficiency: Reducing manual labor leads to lower labor costs, thereby enhancing the efficiency of business processes and yielding financial benefits for companies.
Increased Data Quality: AI-driven systems minimize human errors in data entry, thereby increasing the accuracy and reliability of the extracted data.
Scalability: AI solutions can easily adjust to increasing document volumes or fluctuating workloads without the need for proportionally more resources.
Improved Data Accessibility: Data that has been extracted and digitized from documents is easier to access and can be used more quickly and efficiently for analysis purposes or decision-making processes.
Real-Time Data Processing: Many AI-based systems allow for the immediate processing of incoming documents, enabling decisions to be made based on current information.
Given these advantages, it becomes clear that implementing automatic data extraction – IDA Extraction – represents a significant step towards greater efficiency and competitiveness for companies of any size and industry. Optimizing business processes with such advanced AI technology enables not just meeting the demands of the modern market but actively shaping it.
Use Cases for Automatic PDF Data Extraction
In the modern business world, AI-based data extraction plays a crucial role in optimizing workflows and reducing human errors. By deploying AI, vast amounts of data are not only processed faster but also used more efficiently to make better decisions.
Automated Invoice Processing
Data extraction from invoices allows companies to automatically capture relevant information such as invoice amount, date, and number, speeding up accounting processes and reducing errors.
Customer Identity Verification (KYC)
Banks and financial institutions extract data from identification documents like ID cards or driver’s licenses to quickly and accurately verify the identity of new customers.

Medical Data Capture
In healthcare, patient information is extracted from clinical reports to document treatment courses and improve patient care.
Claim Submission and Management
Insurance companies extract data from claims reports and other documents to process claims faster and minimize fraud cases.
These – among others, such as contract management, HR management, automatic text analysis for research purposes, etc. – application examples demonstrate the wide range of uses for data extraction and how it can revolutionize various industries. The continual development of these technologies contributes to advancing digitalization and opening new horizons for innovation.
Challenges in Automatic PDF Data Extraction
AI-based data extraction plays a pivotal role in modern information processing but faces several obstacles that can affect its efficiency and accuracy.
Diverse Formats: Documents come in various formats, from PDFs to Word documents to images of handwritten notes. The heterogeneity of formats makes standardized data extraction difficult.
Quality of Documents: Poorly scanned documents or photos of documents with low resolution, distortions, and glare can significantly impair text recognition accuracy.
Privacy and Security: Data extraction must adhere to data protection regulations such as GDPR, posing a challenge when extracting personal or sensitive information from documents.
Changes in Document Layout Over Time: Companies and institutions occasionally change their templates and formats, which means that data extraction algorithms must be constantly updated to remain effective.
Faced with these challenges, IDA emerges as a robust solution capable of effectively processing even poorly scanned documents and handwriting with powerful OCR and ICR technologies. By offering on-premises installation, it meets the highest data protection and security requirements, while simple retraining of the software enables quick adjustments to changing document layouts.
Conclusion
The automation of PDF data extraction with AI technologies like OCR and ICR is revolutionizing information processing – from reducing manual errors to significant time and cost savings, and scalability. The process supports extraction from both structured and unstructured documents, with zonal data extraction preferred for the former and LLM Entity Extraction for the latter. Despite challenges such as diverse formats and data protection regulations, the advanced IDA software suite with its robust technology enables efficient and secure data processing. The wide range of use cases – from invoice processing and KYC to medical data capture – highlights the immense value of this technology across various industries, not just by optimizing work processes but also laying the groundwork for data-driven decisions and innovations.
Let’s Connect
Take the next step towards increasing the efficiency of your data processing – discover how our IDA software suite can overcome the challenges of PDF data extraction. Contact us now for a demo!



