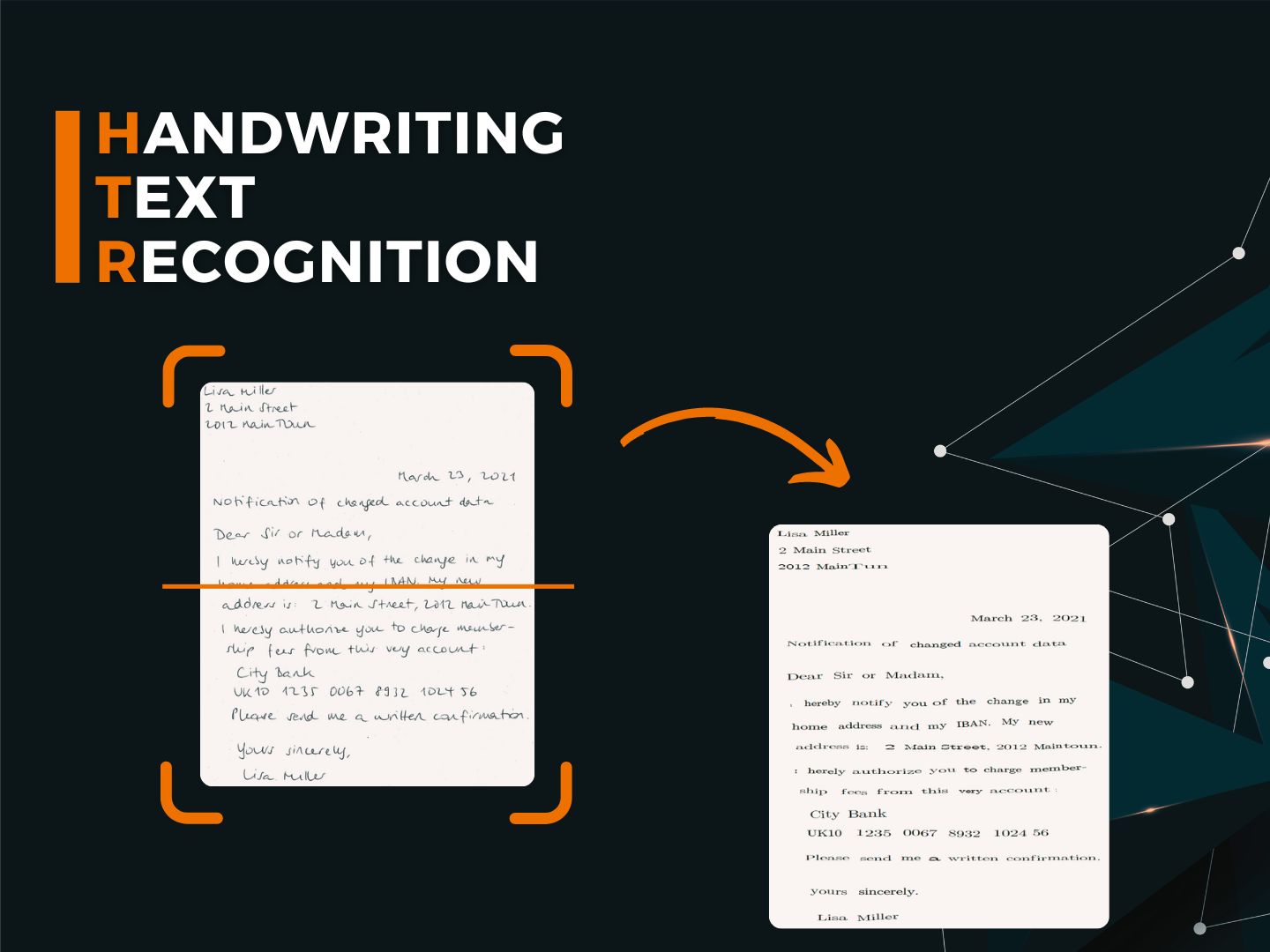
What makes IDA Classification different
Rule-based classification breaks down the moment document layouts or types change. IDA Classification takes a different approach: a learning system that works with minimal training data and adapts without any development effort.
Few-shot learning capabilities
Traditional rule engines take months to configure for new document types and fall apart when requirements shift. IDA Classification uses few-shot learning to analyze visual and textual features simultaneously. Train a new model directly in the browser with just a few sample documents, no coding required.
Document and page classification
IDA offers two classification methods. Document classification evaluates the full content of a document for holistic assignment and is ideal for automated input management. Page classification analyzes individual pages in context of their neighbors, making it the right fit for multi-page files that need to be split into cover letters, CVs, and certificates automatically.
Automatic document separation
Scanned batches with hundreds of consecutive pages still require manual splitting which is time-consuming and error-prone. With IDA, you train a neural network that automatically detects document boundaries within large files. Manual separation during scanning is eliminated entirely, and existing page classification models can be reused.
IDA Classification in action
See how it works in under three minutes.
> 91%
Automation rate
> 80%
Time savings through automation
< 1%
False positives
5 days
Setup time
Technical details
Trusted by leading organizations