Entity Extraction
Eine Schlüsselkomponente moderner Datenverarbeitung

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
In der heutigen digitalen Welt ist die Fähigkeit, Informationen schnell und genau aus Dokumenten zu extrahieren, entscheidender denn je. Unternehmen und Organisationen aller Größen sind täglich mit der Herausforderung konfrontiert, große Mengen unstrukturierter Daten in nutzbare Informationen umzuwandeln. Hier kommt die Entity Extraction im Kontext der intelligenten Dokumentenverarbeitung (IDP) ins Spiel. Dieser Blogpost wird einen detaillierten Blick darauf werfen, was Entity Extraction ist, wie sie im Rahmen von IDP funktioniert und warum sie für Unternehmen essenziell ist.
Was ist Entity Extraction?
Entity Extraction, auch bekannt als Entitätserkennung, ist ein Verfahren der Informationsgewinnung, das darauf abzielt, spezifische Informationen aus einem Text zu identifizieren und zu klassifizieren. Diese Informationen, oder „Entities“, können Namen von Personen, Organisationen, Orte, Daten, Zeiten, Mengen, monetäre Werte und mehr umfassen. Die Extraktion dieser Daten ermöglicht es, unstrukturierte Daten in eine strukturierte Form zu überführen, was deren Analyse und Verarbeitung vereinfacht.
Entity Extraction im IDP-Kontext
Im IDP-Kontext spielt die Entity Extraction eine zentrale Rolle, um aus einer Vielzahl von Dokumenttypen wie Rechnungen, Verträgen, E-Mails und anderen geschäftlichen Unterlagen wertvolle Informationen zu extrahieren. Hier geht es nicht nur darum, bestimmte Daten zu identifizieren, sondern auch darum, das Verhältnis und den Kontext dieser Daten zueinander zu verstehen, um sie korrekt in bestehenden Geschäftsprozessen oder Datenbanken zu integrieren. Indem es automatisch relevante Entitäten wie Vertragsnummern, Beträge, Datumsangaben und beteiligte Parteien erkennt, ermöglicht es IDP-Systemen, Dokumentinhalte effizient zu erfassen und für weiterführende Prozesse vorzubereiten. Die Herausforderung liegt in der Vielfalt der Dokumentformate und der Komplexität der Sprache, welche die Notwendigkeit fortgeschrittener Algorithmen für das Machine Learning und KI unterstreicht, um eine hohe Genauigkeit der Datenextraktion sicherzustellen.
Eine leistungsstarke OCR – die Voraussetzung effizienter Entity Extraction
Eine effiziente Entity Extraction setzt eine leistungsstarke Optische Zeichenerkennung (OCR) voraus, um das Prinzip von „shit in, shit out“ zu vermeiden. Die Qualität und Genauigkeit, mit der Texte aus verschiedenen Dokumenten extrahiert werden, hängen entscheidend von der Fähigkeit der OCR ab, digitale Daten korrekt in bearbeitbaren Text umzuwandeln. Moderne OCR-Systeme sind in der Lage, auch komplexe Schriftarten und Layouts zu erkennen und zu verarbeiten. Diese hohe Erkennungsleistung ist unerlässlich, um sicherzustellen, dass die anschließende Entity Extraction präzise Informationen liefert und somit den ganzen Prozess der Datenverarbeitung optimiert.
Entity Extraction mit IDA
Die innovativen Extraktions-Technologien der IDA – Intelligente Dokumentenanalyse – Software-Suite revolutionieren die Datenerfassung und -verarbeitung, indem sie sowohl für strukturierte als auch für unstrukturierte Dokumente optimierte Lösungen bieten. Diese fortschrittlichen Methoden ermöglichen eine schnelle, präzise Extraktion und Verarbeitung relevanter Daten, unterstützt durch moderne KI-Modelle.
Strukturierte Dokumente – Zonale Datenextraktion
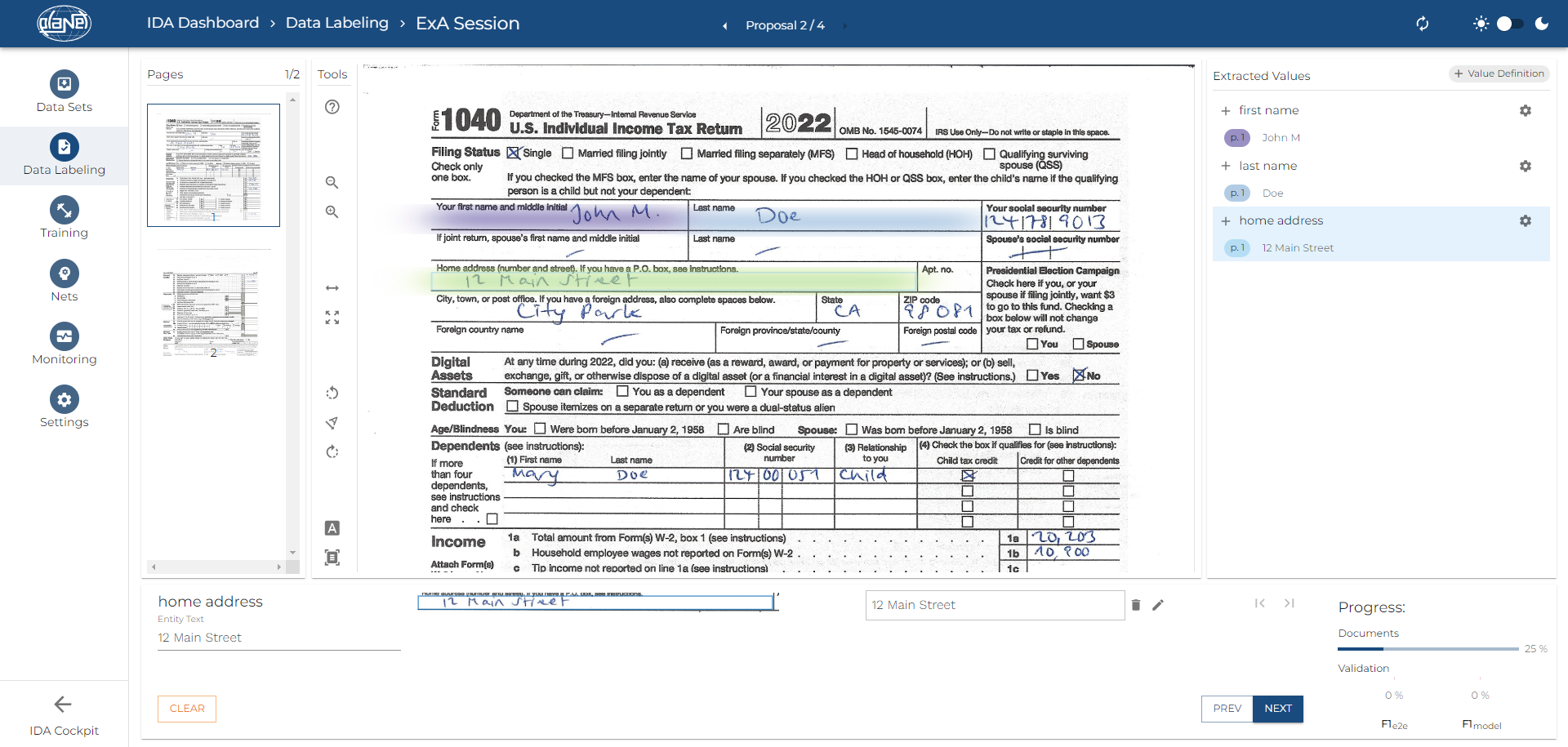
Für strukturierte Dokumente, wie Rechnungen oder Formulare, verwendet IDA die zonale Datenextraktion. Diese Technik nutzt Few-Shot-Learning, um KI-Modelle schnell an spezifische Datenfelder zu adaptieren. Das führt zu einer effizienten und genauen Erfassung der gewünschten Informationen, ohne umfangreiche manuelle Einstellungen oder Vorarbeiten.
Unstrukturierte Dokumente – LLM-basierte Extraktion
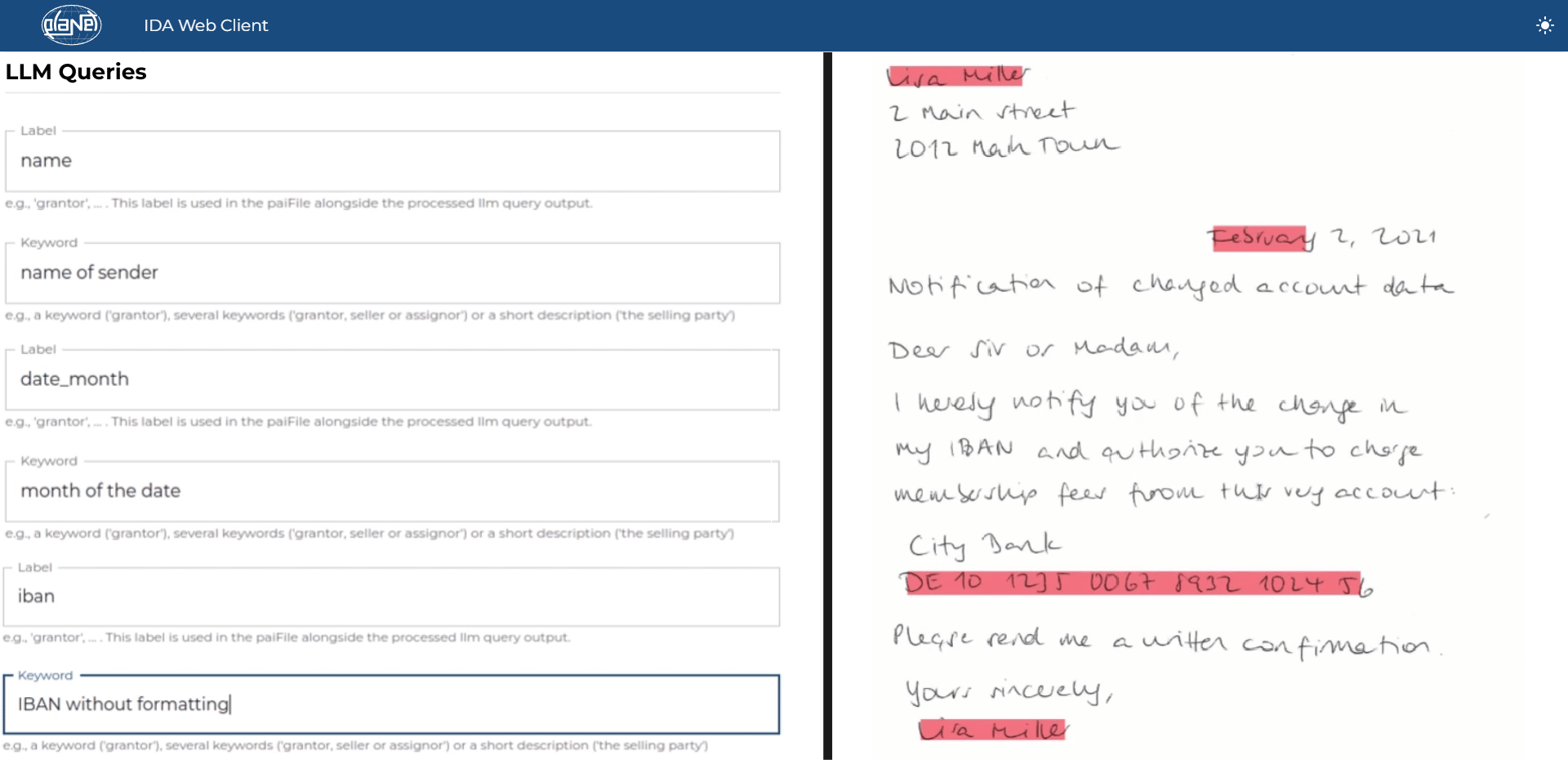
Im Falle unstrukturierter Dokumente, wie E-Mails oder Berichte, setzt IDA auf Extraktion basierend auf großen Sprachmodellen (LLMs). Diese können komplexe Texte verstehen und relevante Informationen herausfiltern. Dank der LLM-Technologie werden selbst aus textreichen, unstrukturierten Dokumenten wertvolle Daten effizient extrahiert, was die Datenerfassung und -analyse erheblich verbessert.
Verbesserung der Datenqualität und -zugänglichkeit
Durch die automatische Extraktion und Klassifikation von Entities wird nicht nur die Geschwindigkeit der Datenverarbeitung erhöht, sondern auch deren Genauigkeit. Fehleranfällige manuelle Eingaben werden minimiert und die Konsistenz der Datenverarbeitung verbessert.
Anwendungsbeispiele der Entity Extraction im IDP-Kontext
Die Anwendung von Entity Extraction im IDP-Kontext umfasst zahlreiche Bereiche, in denen aus Dokumenten spezifische Informationen extrahiert werden. Hier sind einige Beispiele:
Rechnungsverarbeitung
In Rechnungen können mittels Entity Extraction relevante Informationen wie Rechnungsnummer, Datum, Beträge, Steuerinformationen, und Lieferantendetails automatisch erfasst werden. Das vereinfacht die Buchhaltungsprozesse erheblich.
Vertragsmanagement
Beim Vertragsmanagement kann die Entitätserkennung dazu verwendet werden, um Daten wie Vertragsparteien, Start- und Enddaten, Vertragsbedingungen, Zahlungsklauseln und Strafen aus Verträgen zu extrahieren. Dies hilft bei der Automatisierung von Compliance-Checks und Vertragsüberwachung.

Kunden-Onboarding
Im Bank- und Versicherungswesen ist die Entity Extraction nützlich, um aus Ausweisdokumenten Informationen wie Namen, Geburtsdatum, Adressen und weitere persönliche Details automatisch zu entnehmen und in Kundendatenbanken einzupflegen.
E-Mail- und Kommunikationsmanagement
Extraktion von Informationen wie Kontaktangaben, Termine, Anfragen oder Auftragsnummern aus eingehenden E-Mails oder Nachrichten, um die Bearbeitung zu beschleunigen und relevante Prozesse anzustoßen.
Durch den Einsatz von Entity Extraction in diesen und weiteren Anwendungsfällen können Unternehmen nicht nur Zeit und Ressourcen sparen, sondern auch die Datenqualität verbessern und menschliche Fehler reduzieren.
Fazit
Entity Extraction ist ein unverzichtbarer Bestandteil der intelligenten Dokumentenverarbeitung, der Unternehmen ermöglicht, das volle Potenzial ihrer Daten zu erschließen. Durch die Automatisierung der Datenerfassung und -klassifikation können Organisationen ihre Effizienz steigern, die Genauigkeit der Datenverarbeitung verbessern und besser informierte Entscheidungen treffen. Mit der kontinuierlichen Verbesserung der zugrundeliegenden Technologien wird die Entity Extraction weiterhin eine Schlüsselrolle bei der Transformation der Art und Weise spielen, wie wir mit Informationen umgehen.
Let’s Connect
Möchten Sie erfahren, wie unsere Technologien Ihnen helfen können, Ihr Datenmanagement zu automatisieren? Zögern Sie nicht, uns zu kontaktieren! Wir stehen Ihnen gerne zur Verfügung, um Ihre spezifischen Anforderungen zu besprechen und maßgeschneiderte Lösungen anzubieten, die Ihren Geschäftsprozessen einen wahren Mehrwert bringen. Nehmen Sie jetzt Kontakt mit uns auf, um den ersten Schritt in Richtung effizienterer Datenverarbeitung und besserer Entscheidungsfindung zu machen.