PDF-Datenextraktion
Daten mit KI effizient und automatisch extrahieren

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
In einer Welt, in der Daten als das neue Gold gelten, ist die manuelle Extraktion von Informationen aus Dokumenten – PDF, PNG, JPG, etc. – nicht nur zeitaufwendig, sondern auch anfällig für Fehler. Hier zeigt sich die wahre Kraft von Software zur intelligenten Dokumentenverarbeitung (IDP). Moderne OCR- (Optische Zeichenerkennung) und ICR- (Intelligente Zeichenerkennung) Technologien, wie sie in der fortschrittlichen IDA Software-Suite zum Einsatz kommen, spielen eine entscheidende Rolle dabei, den Herausforderungen der automatischen Datenextraktion effektiv zu begegnen. Ohne solche Technologien wäre man einem ständigen Kreislauf aus „Shit in, Shit out“ unterworfen, mit endloser manueller Nachbearbeitung als Folge.
Was ist PDF-Datenextraktion?
PDF-Datenextraktion ist der Prozess, bei dem Informationen aus PDF-Dokumenten in eine strukturierte, maschinenlesbare Form überführt werden. Diese Technik ist wesentlich, da PDFs weit verbreitet sind, um Informationen zu verbreiten und zu speichern. Die Herausforderung dabei ist, Daten so zu extrahieren, dass sie direkt für weitere Analysen oder die Verarbeitung nutzbar sind. Fortschrittliche Technologien wie OCR und ICR spielen eine zentrale Rolle, indem sie komplexe Informationen erkennen und extrahieren, um statische PDF-Inhalte in dynamische Daten umzuwandeln, die einen echten Mehrwert bieten.
PDF-Datenextraktion im IDP Prozess
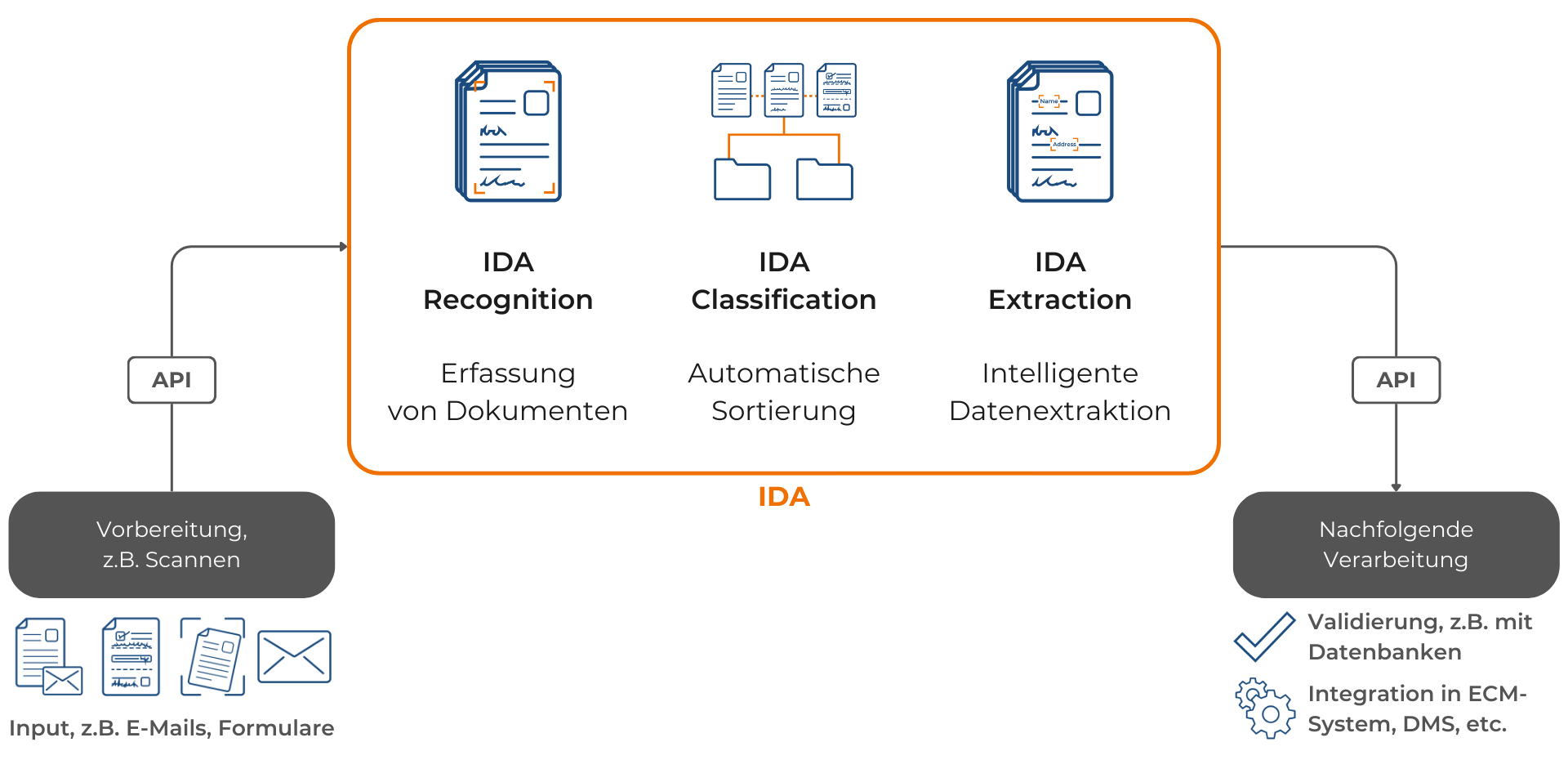
Die Datenextraktion spielt eine zentrale Rolle im Prozess der intelligenten Dokumentenverarbeitung, der nach der Vorbereitung (z.B. Scannen) von Dokumenten beginnt. Die digitale Erfassung von Dokumenten mit OCR- und ICR-Technologien ist der entscheidende Faktor, der mit seiner Qualität den Grundstein für alle nachfolgenden Verarbeitungsschritte legt. Nach der Erfassung können Dokumente mittels KI klassifiziert und relevante Daten aus den PDF-Dokumenten extrahiert werden. Die anschließende Phase integriert die aufbereiteten Daten durch Validierung gegenüber Datenbanken in bestehende ECM-System oder ins DMS, was nicht nur die Geschäftsprozesse beschleunigt, sondern auch für einen effizienten Informationsfluss sorgt.
Welche Arten der PDF-Datenextraktion gibt es?
Bei der automatischen Datenextraktion aus Dokumenten unterscheiden wir grundsätzlich zwischen zwei Haupttechniken, deren Anwendung vom Dokumententyp abhängt.
Zonale Datenextraktion – für strukturierte Dokumente
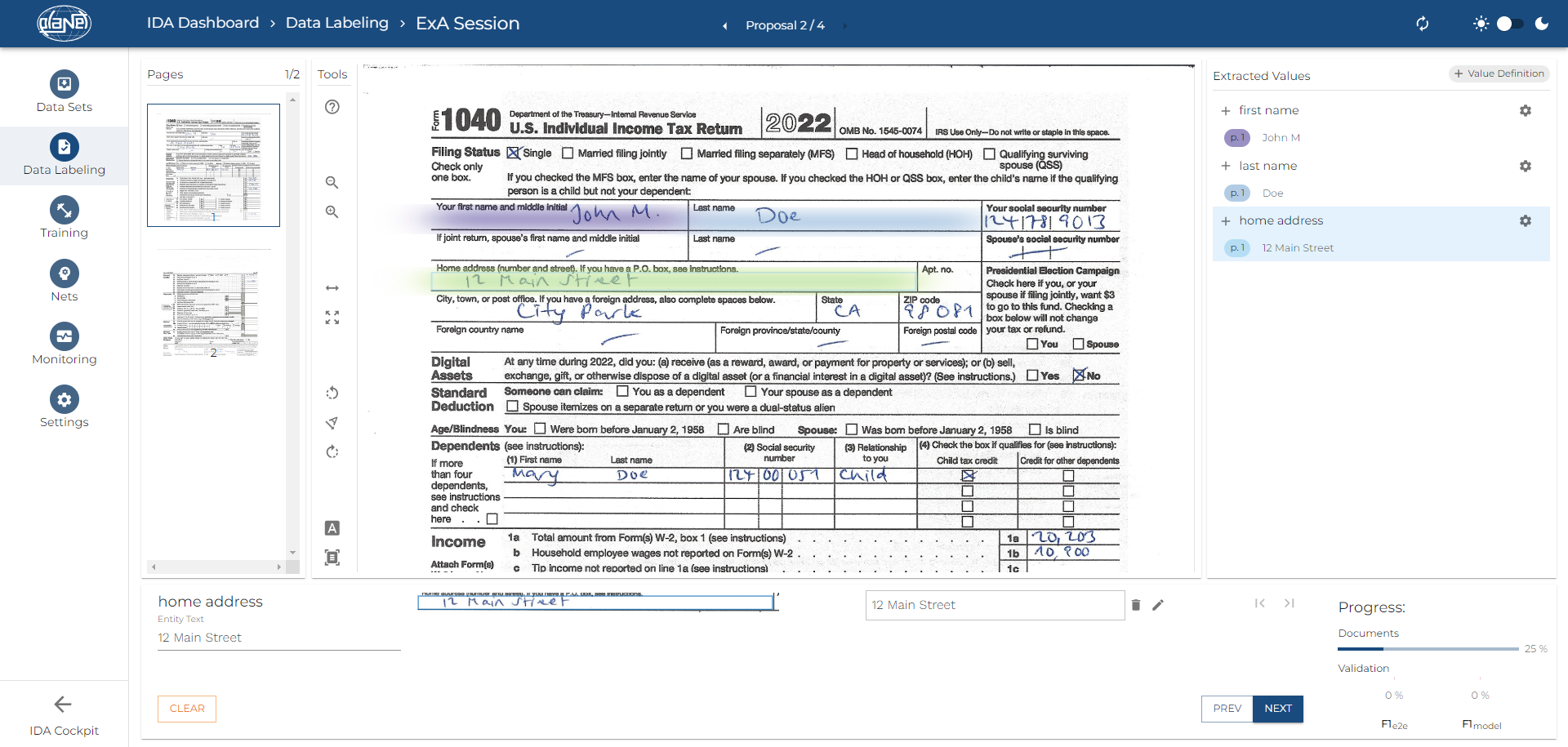
Die Zonale Datenextraktion eignet sich hervorragend für strukturierte und semistrukturierte Dokumente, wie Formulare, Rechnungen, etc., bei denen bestimmte Daten in fest definierten Bereichen zu finden sind. Während des Trainingsprozesses der Künstlichen Intelligenz (KI) markiert der Nutzer in verschiedenen Beispiel-Dokumenten die spezifischen Zonen, aus denen Informationen extrahiert werden sollen. Nach Abschluss des Trainings ist die KI in der Lage, aus neuen, eingehenden Dokumenten automatisch Daten aus den entsprechenden Bereichen zu extrahieren.
LLM Entity Extraction – für unstrukturierte Dokumente
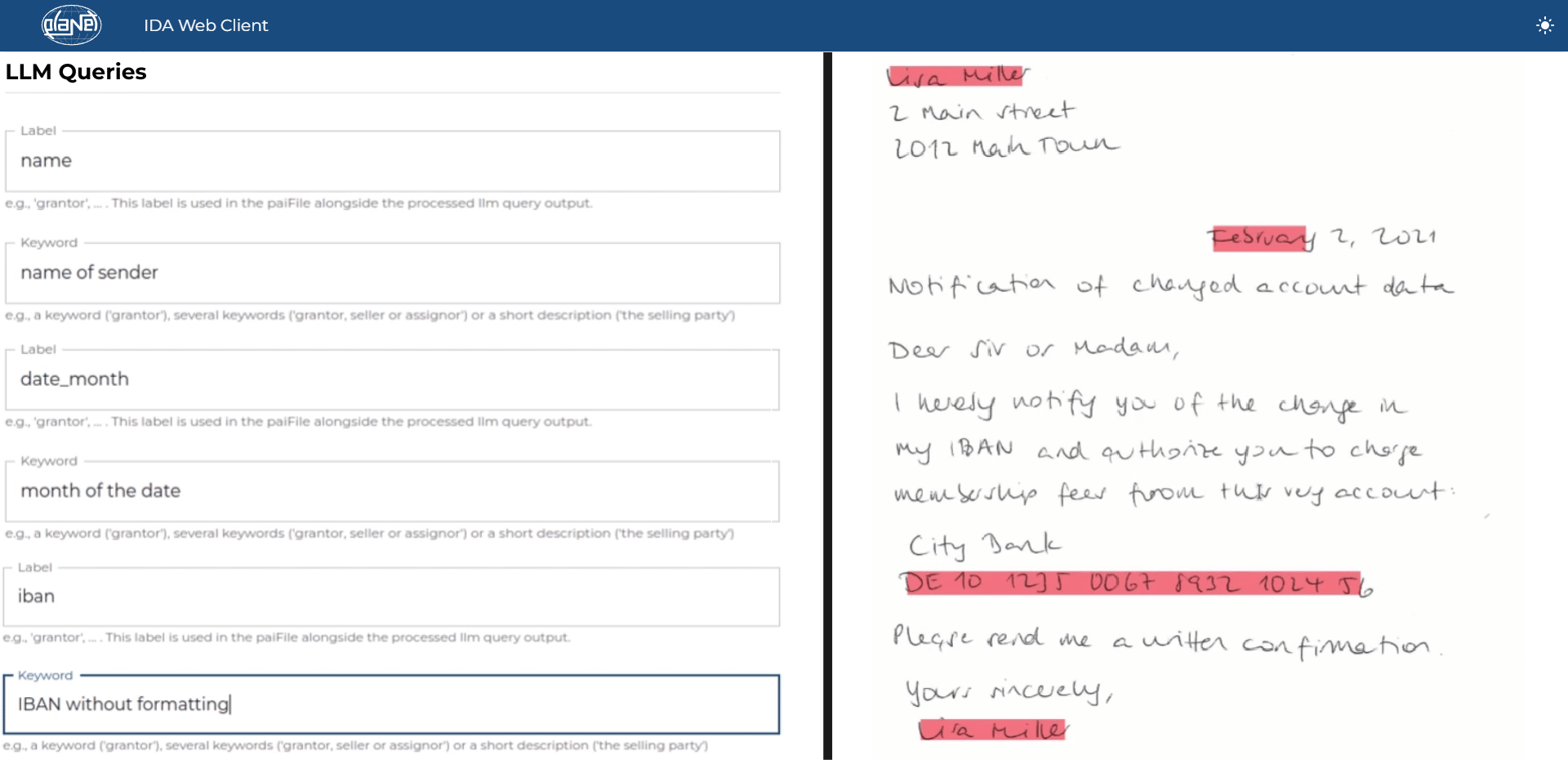
Die LLM (Large Language Model) Entity Extraction ist dagegen optimal für die Handhabung unstrukturierter Dokumente ohne festes Layout, wie Verträgen, Anschreiben, etc. Diese Technik basiert auf Prompts, um relevante Informationen zu erkennen und zu extrahieren. Die LLM Entity Extraction kann sich flexibel an verschiedene Formate und Kontexte anpassen.
Zusammen ermöglichen diese beiden Ansätze eine umfassende und flexible Datenextraktion aus allen Dokumenttypen, was sie zu unverzichtbaren Werkzeugen in der digitalen Datenverarbeitung macht.
Welche Vorteile bringt die PDF-Datenextraktion mit sich?
Im Zeitalter der Digitalisierung und Big Data stehen Unternehmen vor der Herausforderung, riesige Mengen an Daten effizient zu verarbeiten und nutzbar zu machen. Hier bietet die automatische Datenextraktion mittels KI eine Lösung, um diesen Herausforderungen gerecht zu werden.
Zeitersparnis: Durch die Automatisierung des Datenextraktionsprozesses können Unternehmen signifikante Zeitersparnisse realisieren, da der manuelle Aufwand des Lesens, Verstehens und Eingebens von Daten aus Dokumenten in digitale Systeme entfällt.
Kosteneffizienz: Die Reduzierung des manuellen Arbeitsaufwands führt zu geringeren Arbeitskosten und kann somit die Effizienz von Geschäftsprozessen steigern, wodurch Unternehmen finanziell profitieren.
Erhöhung der Datenqualität: KI-gesteuerte Systeme minimieren menschliche Fehler bei der Dateneingabe und erhöhen dadurch die Genauigkeit und Zuverlässigkeit der extrahierten Daten.
Skalierbarkeit: KI-Lösungen können problemlos an steigende Dokumentenmengen oder schwankende Arbeitslasten angepasst werden, ohne dass dafür proportional mehr Ressourcen erforderlich sind.
Verbesserte Datenzugänglichkeit: Daten, die aus Dokumenten extrahiert und digitalisiert wurden, sind leichter zugänglich und können für Analysezwecke oder Entscheidungsfindungsprozesse schneller und effizient genutzt werden.
Real-Time Datenverarbeitung: Viele KI-basierte Systeme ermöglichen die sofortige Bearbeitung eingehender Dokumente, wodurch Entscheidungen auf der Basis aktueller Informationen getroffen werden können.
Angesichts dieser Vorteile wird deutlich, dass die Implementierung von automatischer Datenextraktion – IDA Extraction – für Unternehmen jeglicher Größe und Branche einen bedeutsamen Schritt hin zu mehr Effizienz und Wettbewerbsfähigkeit darstellt. Die Optimierung von Geschäftsprozessen durch derart fortschrittliche Technologie ermöglicht es, den Anforderungen des modernen Marktes nicht nur gerecht zu werden, sondern ihn aktiv mitzugestalten.
Anwendungsfälle der automatischen PDF-Datenextraktion
In der modernen Geschäftswelt spielt die KI-basierte Datenextraktion eine entscheidende Rolle bei der Optimierung von Arbeitsprozessen und der Reduzierung von menschlichen Fehlern. Durch den Einsatz künstlicher Intelligenz werden enorme Datenmengen nicht nur schneller verarbeitet, sondern auch effizienter genutzt, um bessere Entscheidungen zu treffen.
Automatisierte Rechnungsbearbeitung
Die Datenextraktion aus Rechnungen ermöglicht Unternehmen, relevante Informationen wie Rechnungsbetrag, -datum und -nummer automatisch zu erfassen, was die Buchhaltungsprozesse beschleunigt und Fehler reduziert.
Kundenidentitätsprüfung (KYC)
Banken und Finanzinstitute extrahieren Daten aus Identifikationsdokumenten wie Ausweisen oder Führerscheinen, um die Identität von Neukunden schnell und präzise zu verifizieren.

Medizinische Datenerfassung
Im Gesundheitswesen werden Patienteninformationen aus klinischen Berichten extrahiert, um Behandlungsverläufe zu dokumentieren und die Patientenversorgung zu verbessern.
Einreichung und Verwaltung von Versicherungsansprüchen
Versicherungsunternehmen extrahieren Daten aus Schadensmeldungen und anderen Dokumenten, um Ansprüche schneller zu bearbeiten und Betrugsfälle zu minimieren.
Diese – und weitere, z.B. Vertragsmanagement, Personalmanagement, Automatische Textanalyse für Forschungszwecke, etc. – Anwendungsbeispiele zeigen, wie breit gefächert die Einsatzmöglichkeiten für die Datenextraktion sind und wie sie verschiedenste Branchen revolutionieren können. Die kontinuierliche Weiterentwicklung dieser Technologien trägt dazu bei, die Digitalisierung voranzutreiben und neue Innovationshorizonte zu eröffnen.
Herausforderungen bei der automatischen PDF-Datenextraktion
Die KI-basierte Datenextraktion spielt eine wichtige Rolle in der modernen Informationsverarbeitung, stößt jedoch auf verschiedene Hindernisse, die ihre Effizienz und Genauigkeit beeinträchtigen.
Unterschiedliche Formate: Dokumente kommen in verschiedenen Formaten vor, von PDFs über Word-Dokumente bis hin zu handgeschriebenen Notizen. Die Heterogenität der Formate erschwert eine standardisierte Datenextraktion.
Qualität der Dokumente: Schlecht gescannte Dokumente oder Fotos von Dokumenten mit niedriger Auflösung, Verzerrungen und Lichtreflexen können die Erkennungsgenauigkeit von Text erheblich beeinträchtigen.
Datenschutz und Sicherheit: Die Datenextraktion muss Datenschutzbestimmungen wie der DSGVO folgen, was eine Herausforderung darstellt, wenn personenbezogene oder sensible Informationen aus Dokumenten extrahiert werden müssen.
Änderungen im Dokumenten-Layout über die Zeit: Unternehmen und Verwaltungen ändern gelegentlich ihre Vorlagen und Formate, was bedeutet, dass Algorithmen zur Datenextraktion ständig angepasst werden müssen, um effektiv zu bleiben.
Angesichts dieser Herausforderungen zeigt sich IDA als robuste Lösung, die mit leistungsfähigen OCR- und ICR-Technologien selbst schlecht gescannte Dokumente und Handschriften effektiv verarbeiten kann. Durch die Möglichkeit einer On-Premises-Installation wird höchsten Datenschutz- und Sicherheitsanforderungen Rechnung getragen, während simples Nachtraining der Software schnelle Anpassungen an sich ändernde Dokumentenlayouts ermöglicht.
Fazit
Die Automatisierung der PDF-Datenextraktion mittels KI-Technologien wie OCR und ICR revolutioniert die Informationsverarbeitung – von der Reduzierung manueller Fehler über erhebliche Zeit- und Kosteneinsparungen bis hin zur Skalierbarkeit. Der Prozess unterstützt sowohl die Extraktion aus strukturierten als auch unstrukturierten Dokumenten, wobei zonale Datenextraktion für erstere und LLM Entity Extraction für letztere bevorzugt wird. Trotz Herausforderungen wie unterschiedliche Formate und Datenschutzbestimmungen ermöglicht die fortschrittliche IDA Software-Suite mit ihrer robusten Technologie eine effiziente und sichere Datenverarbeitung. Die breite Palette von Anwendungsfällen – von der Rechnungsbearbeitung über KYC bis hin zur medizinischen Datenerfassung – unterstreicht den immensen Nutzen dieser Technologie für diverse Branchen, indem sie nicht nur die Arbeitsprozesse optimiert, sondern auch die Grundlage für datengetriebene Entscheidungen und Innovationen schafft.
Let’s Connect
Machen Sie den nächsten Schritt zur Effizienzsteigerung Ihrer Datenverarbeitung – entdecken Sie, wie unsere IDA Software-Suite die Herausforderungen der PDF-Datenextraktion meistern kann. Kontaktieren Sie uns jetzt für eine Demo!